原理分析
1.冒泡排序:
交换排序顾名思义就是通过元素的两两比较,判断是否符合要求,如过不符合就交换位置来达到排序的目的。冒泡排序名字的由来就是因为在交换过程中,类似水冒泡,小(大)的元素经过不断的交换由水底慢慢的浮到水的顶端。
冒泡排序的思想就是利用的比较交换,利用循环将第 i 小或者大的元素归位,归位操作利用的是对 n 个元素中相邻的两个进行比较,如果顺序正确就不交换,如果顺序错误就进行位置的交换。通过重复的循环访问数组,直到没有可以交换的元素,那么整个排序就已经完成了。
冒泡排序性能分析:
1.空间效率:仅使用常数个辅助单元,空间复杂度为Ο(1)。
2.时间效率:最坏情况与平均情况均为Ο(n²)。
2.快速排序:
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
实现步骤:
1.从数列中挑出一个元素,称为 “基准”(pivot);
2.重新排序数列,所有元素比基准值小的摆放在基准前面,所有元 素比基准值大的摆在基准的 后面(相同的数可以到任一边)。在这个 分区退出之后,该基准就处于数列的中间位置。这个称为分区操 作;
3.递归地把小于基准值元素的子数列和大于基准值元素的子数列排序;
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
效率对比
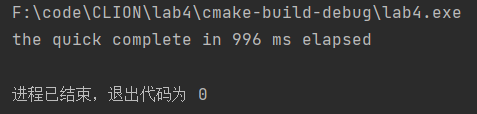
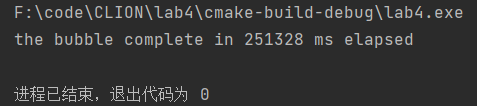
生成了一万个随机数后利用两种排序法的时间对比
快速排序算法:
冒泡排序算法:
完整代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| #include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
void swap(int *a,int *b){
int t;
t=*a;
*a=*b;
*b=t;
}
void Quicksort(int *a,int left,int right){
if(left>=right)
return;
int pivot = a[right];
int m=left,n=right-1;
while(m<n){
while(a[m] < pivot && m<n)
m++;
while(a[n] >= pivot && m<n)
n--;
swap(&a[m], &a[n]);
}
if(a[m]>=a[right])
swap(&a[m], &a[right]);
else
m++;
if(m)
Quicksort(a, left, m - 1);
Quicksort(a, m + 1, right);
}
void Quick_Sort(int *a,int n){
Quicksort(a,0,n-1);
}
void Bubble_Sort(int *a,int n){
int i ,p ;
int flag = 0;
for(p=n-1;p>=0;p--){
for(i=0;i<p;i++){
if(a[i] > a[i+1]){
swap(&a[i],&a[i+1]);
flag = 1;
}
}
if(flag == 0) break;
}
}
int main() {
struct timeval start, end;
gettimeofday(&start, NULL);
int L[10000];
int i;
for(i=0;i<10000;i++){
L[i] = rand();
}
Bubble_Sort(L,10000);
printf("the bubble complete in ");
gettimeofday(&end, NULL);
long elapsed = (end.tv_sec - start.tv_sec)*1000000.0 + end.tv_usec - start.tv_usec;
printf("%.ld ms elapsed\n", elapsed);
return 0;
}
|
结论
快速排序算法在运行时间上明显少于冒泡排序算法运行时间。