汇编语言
汇编语言
第一章 基础知识
内存的读写和地址空间
CPU 对存储器的读写
CPU 想要进行数据的读写,必须和外部器件进行三类信息的交互:
- 存储单元的地址(地址信息)
- 器件的选择,读或写命令(控制信息)
- 读或写的数据(数据信息)
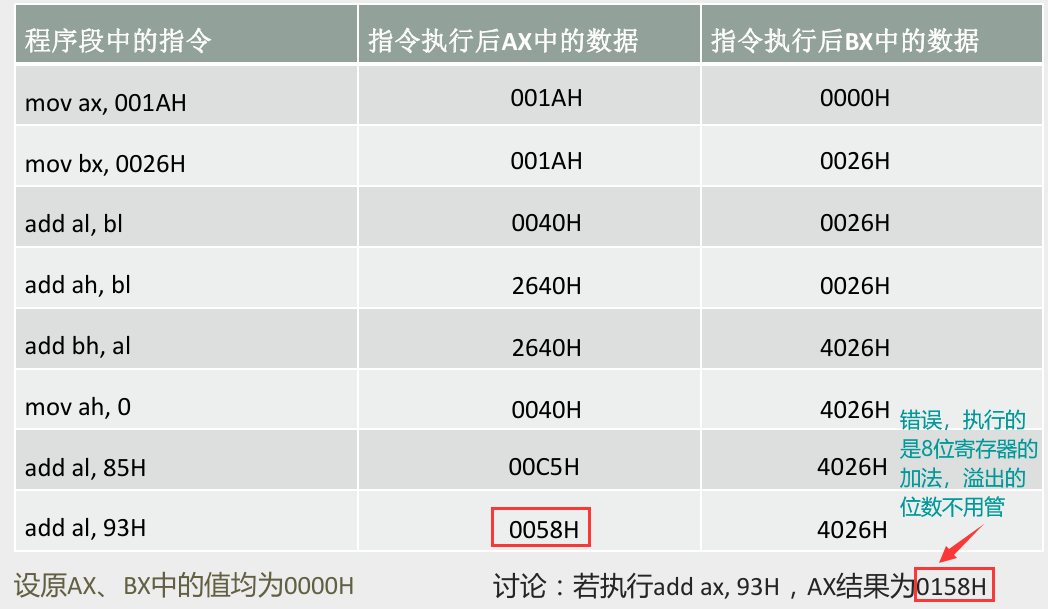
内存地址空间
- 定义:CPU 地址总线宽度为 ,寻址空间为 字节。
- 举例:8086 CPU 的地址总线宽度为 20,那么可以寻址的内存单位个数为 =1 MB,称其内存地址空间为 1 MB。
- 将各类存储器看作一个逻辑存储器(统一编址)
- 所有的物理存储器被看作一个由若干存储单元组成的逻辑存储器;
- 每个物理存储器在这个逻辑存储器中占有一个地址段,即一段地址空间。
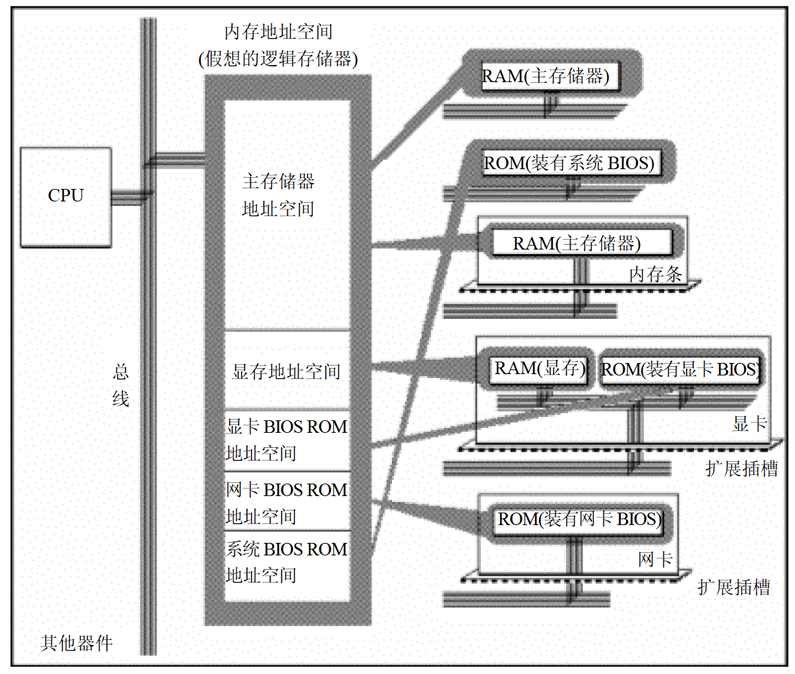
- 举例:8086 PC 机的内存地址空间分配基本情况:

第二章 寄存器
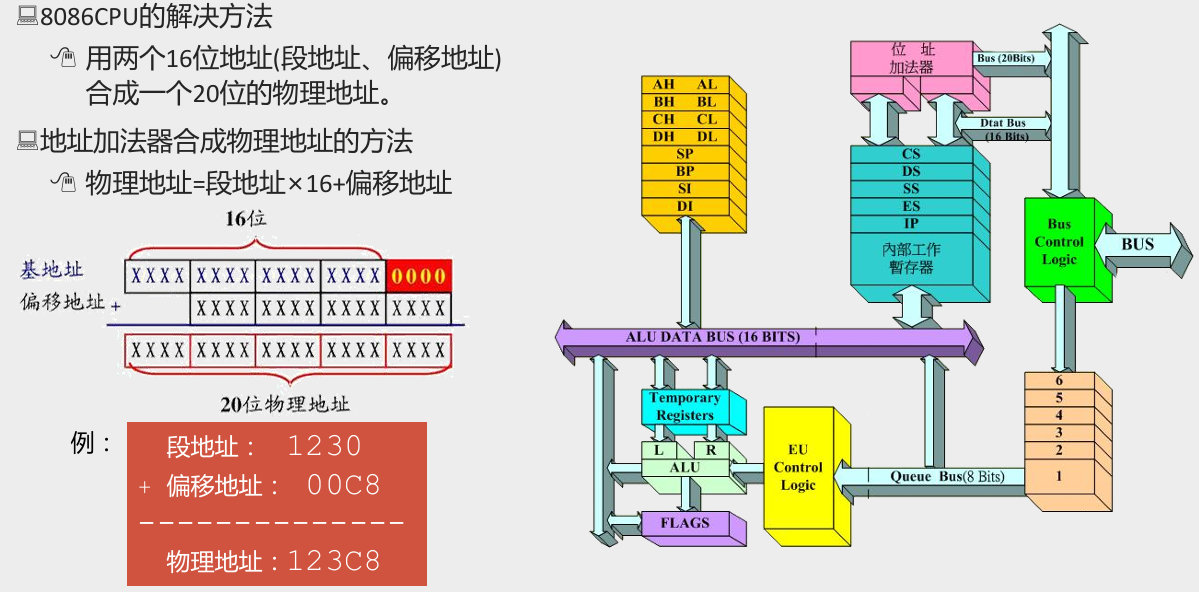
一个典型的CPU由运算器、控制器、寄存器等器件组成,这些器件靠内部总线相连。
区分内部总线与外部总线:
- 内部总线实现CPU内部各个器件之间的联系。
- 外部总线实现CPU和主板上其他器件的联系。
简单而言,在CPU中:
- 运算器进行信息处理;
- 寄存器进行信息存储;
- 控制器控制各种器件进行工作;
- 内部总线连接各种器件,在它们之间进行数据传送;
其中,寄存器是 CPU 中程序员可以用指令读写的部件,可以通过改变各种寄存器中的内容来实现对 CPU 的控制。
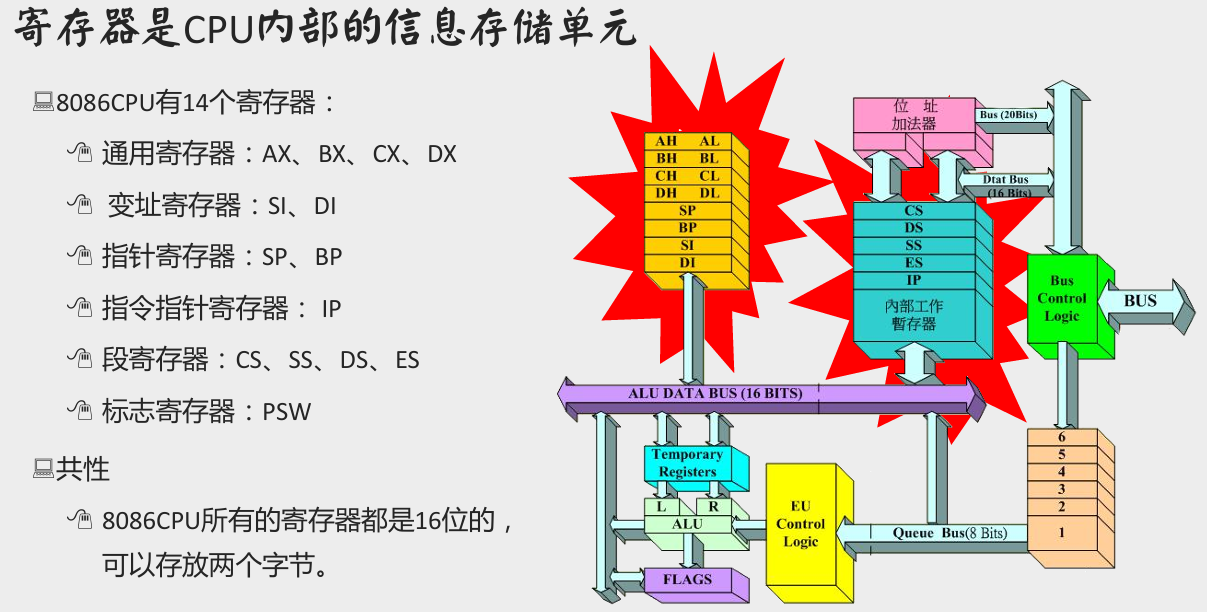
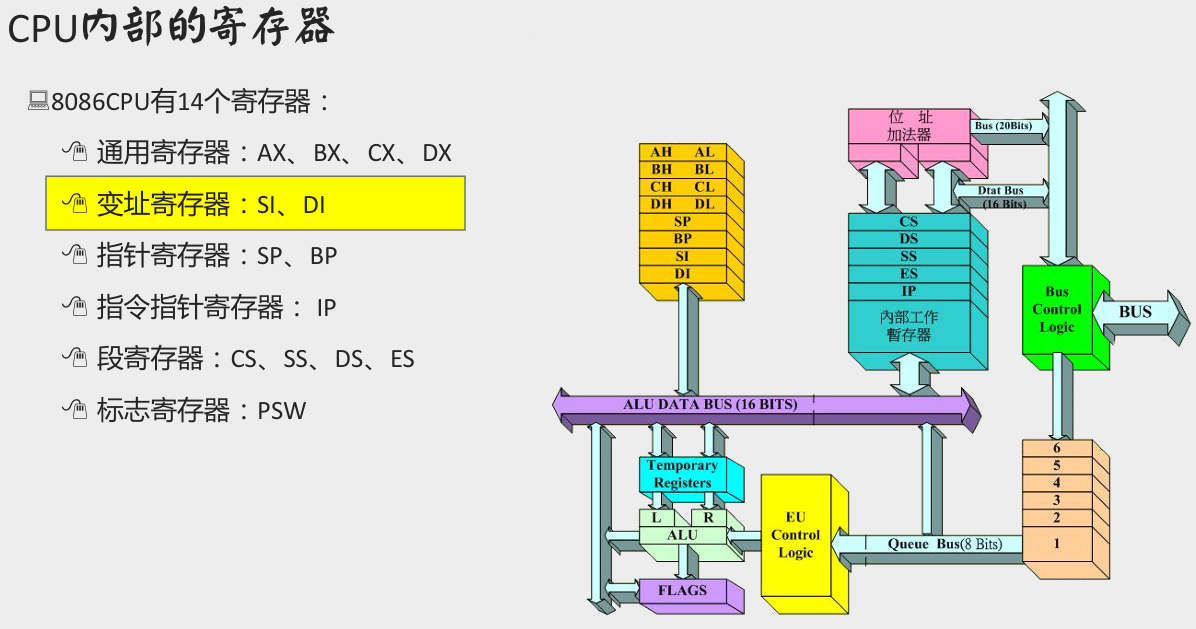
通用寄存器
8086CPU中所有寄存器都是16位的,可以存放两个字节的数据。
存放一般性数据的寄存器成为通用寄存器,有AX、BX、CX、DX四个通用寄存器。
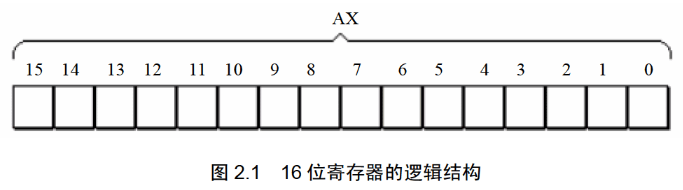
为了保证与上一代的8位寄存器兼容,8086CPU中的通用寄存器AX、BX、CX、DX都可以分为两个可以独立使用的8位寄存器。
- AX可分为AH和AL;
- BX可分为BH和BL;
- CX可分为CH和CL;
- DX可分为DH和DL;

字在寄存器的存储
-
8086是16位CPU
- 8086的字长(word size)为16bit
- 字节:记为Byte,一个字节由8个bit组成,可以存在8位寄存器中;
- 字:记为Word,对于16位的8086CPU而言,一个字由两个字节组成,这两个字节分别称为这个字的高位字节和低位字节。
-
需要特别注意字的定义:
- 计算机进行数据处理时,一次存取、加工和传送的数据长度称为字。然而,这可能会根据系统的不同而变化。例如,在
32位的系统中,一个字由32位组成。在64位的系统中,一个字由64位组成。所以,虽然16位通常被称为一个字,但这可能会根据具体的计算机系统而有所不同。
- 计算机进行数据处理时,一次存取、加工和传送的数据长度称为字。然而,这可能会根据系统的不同而变化。例如,在
几条汇编指令
- 通过汇编指令控制 CPU 进行工作,下表有常见的几条指令:
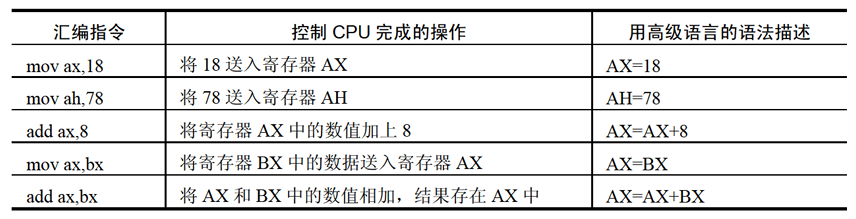
- 注意:汇编语言不区分大小写

确定物理地址的方法
物理地址
- CPU 访问内存单元时要给出内存单元的地址。
- 所有的内存单元构成的存储空间是一个一维的线性空间。
- 每一个内存单元在这个空间中都有唯一的地址,这个唯一的地址称为物理地址。
8086 CPU 物理地址示例
示例
- 8086 CPU 有
20位地址总线,可传送20位地址,寻址能力为1M。 - 8086 是
16位结构的 CPU- 运算器一次最多可以处理
16位的数据,寄存器的最大宽度为16位。 - 在 8086 CPU 内部处理的、传输、暂存的地址也是
16位,寻址能力也只有64KB!
- 运算器一次最多可以处理
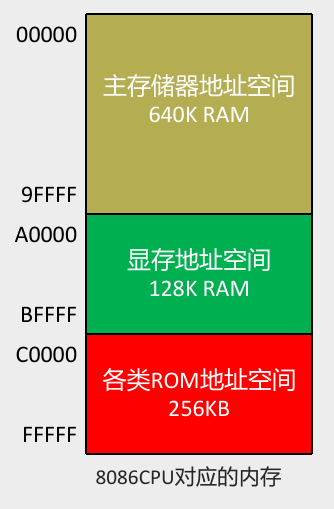
解决方案
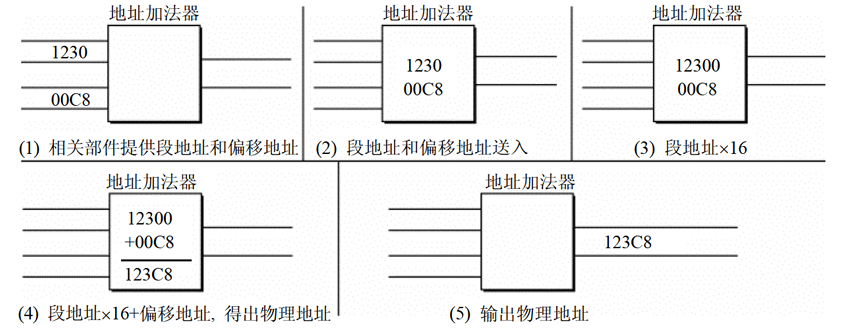
- 方法:物理地址=段地址×16+偏移地址
本质含义
- 要解决的问题:
- 用两个 16 位的地址(段地址、偏移地址),相加得到一个
20位的物理地址。
- 用两个 16 位的地址(段地址、偏移地址),相加得到一个
- 本质含义:
- CPU 在访问内存时,用一个基础地址(段地址×16)和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。
段的概念
用分段的方式管理内存
- 需要注意的是,内存并没有分段,段的划分来自于 CPU。

同一段内存,多种分段方案
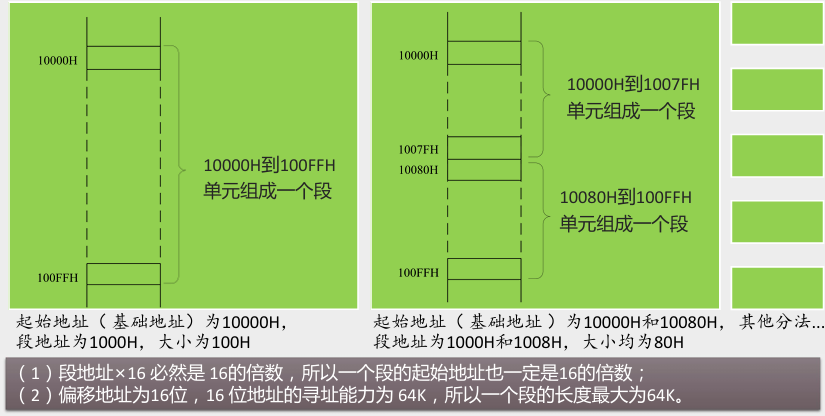
用不同的段地址和偏移地址形成同一个物理地址
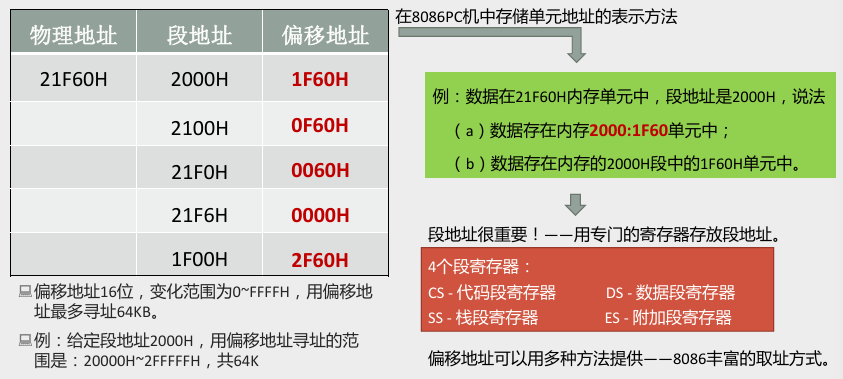
段寄存器
- 由上述章节我们知道,8086 CPU 在访问内存时要由相关部件提供内存单元的段地址和偏移地址,送入地址加法器合成物理地址。
- 其中段地址在 8086 CPU 的
4个段寄存器中存放,分别是:CS、DS、SS、ES,当 8086 CPU 要访问内存时由这 4 个段寄存器提供内存单元的段地址。
CS 和 IP 寄存器
CS和IP寄存器是 8086 CPU 中两个最关键的寄存器,它们指示了 CPU 当前要读取指令的地址。CS为代码段寄存器,IP为指令指针寄存器。

- 在 8086 CPU 加电启动或者复位后,
CS和IP被设置为CS=FFFFH,IP=0000H,即在 8086 PC 刚启动时,CPU 从内存FFFF0H单元中读取指令执行,FFFF0H单元中的指令是 8086 PC 开机后执行的第一条指令。 - 简而言之,
CS和IP寄存器提供了 CPU 要执行指令的地址。 - 我们知道,在内存中,指令和数据没有任何区别,都是二进制信息,CPU 在工作时的时候把有的信息看作指令,有的信息看作数据。
- 那么应该如何区分指令和数据呢?
- 可以看到的是,CPU 将
CS和IP寄存器指向的内存单元中的内容看作指令,因为在任何时候,CS和IP寄存器中的内容分别代表指令的段地址和偏移地址,使用它们合成指令的物理地址,通过物理地址到内存中读取指令码并执行。 - 那么,可以认为如果内存中的一段信息曾被 CPU 执行过的话,那么它所在的内存单元必然被
CS和IP寄存器指向过。
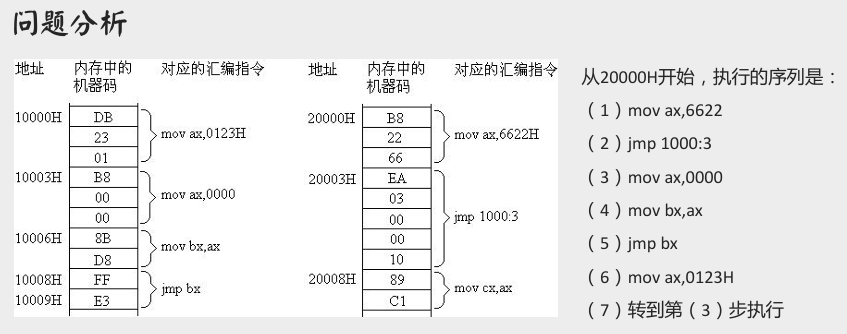
修改 CS、IP 的指令
- 事实:执行何处的指令,取决于
CS和IP寄存器。 - 应用:可以通过改变
CS和IP寄存器中的内容,来控制 CPU 要执行的目标指令。
转移指令 jmp

内存中字的存储

字单元

DS 和 [address]
CPU 从内存单元中读取地址

字的传送
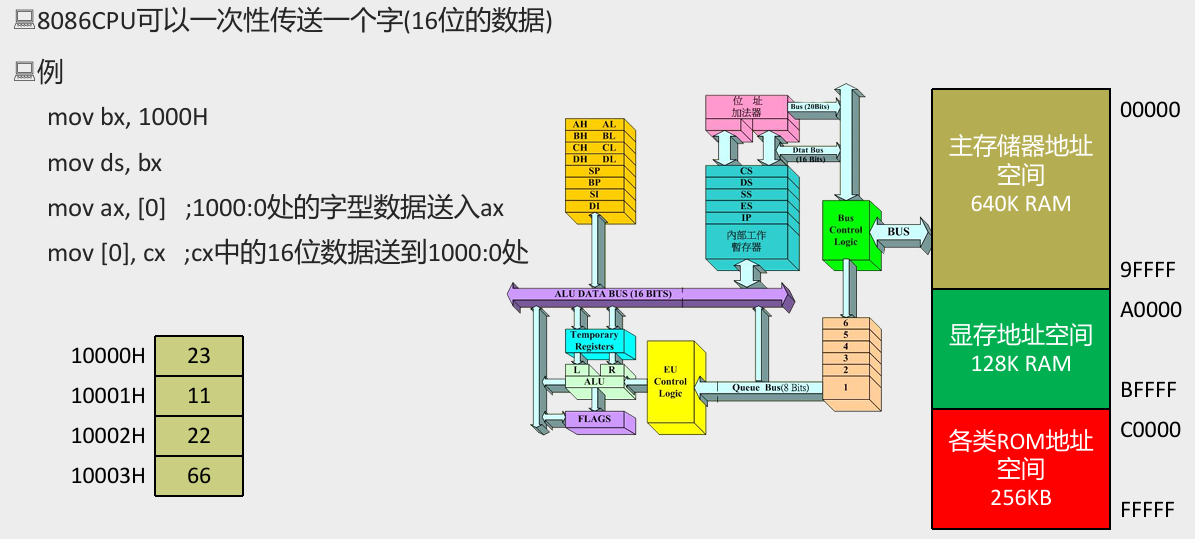
- 例题:

- 分析:
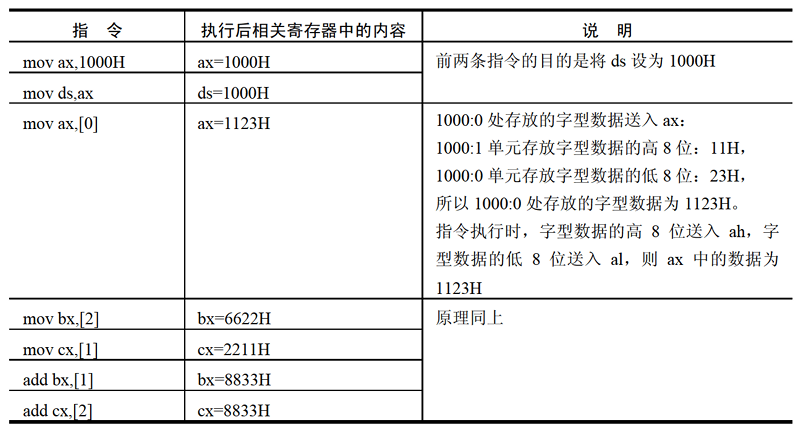
对内存单元数据的访问

三个常用指令总结
mov 指令

加法 add 和减法 sub 指令

用 DS 和[address]形式访问内存中数据段方法小结
- 字在内存中存储时,要用两个地址连续的内存单元来存放,字的低位字节存放在低地址单元中,高位字节存放再高地址单元中。
- 用
mov指令要访问内存单元,可以在mov指令中只给出单元的偏移地址,此时,段地址默认在DS寄存器中。 [address]表示一个偏移地址为address的内存单元。- 在内存和寄存器之间传送字型数据时,高地址单元和高 8 位寄存器、 低地址单元和低 8 位寄存器相对应。
mov、add、sub是具有两个操作对象的指令,访问内存中的数据段(对照:jmp是具有一个操作对象的指令,对应内存中的代码段)。- 可以根据自己的推测,在
Debug模式中实验指令的新格式。
栈及栈操作的实现
栈结构

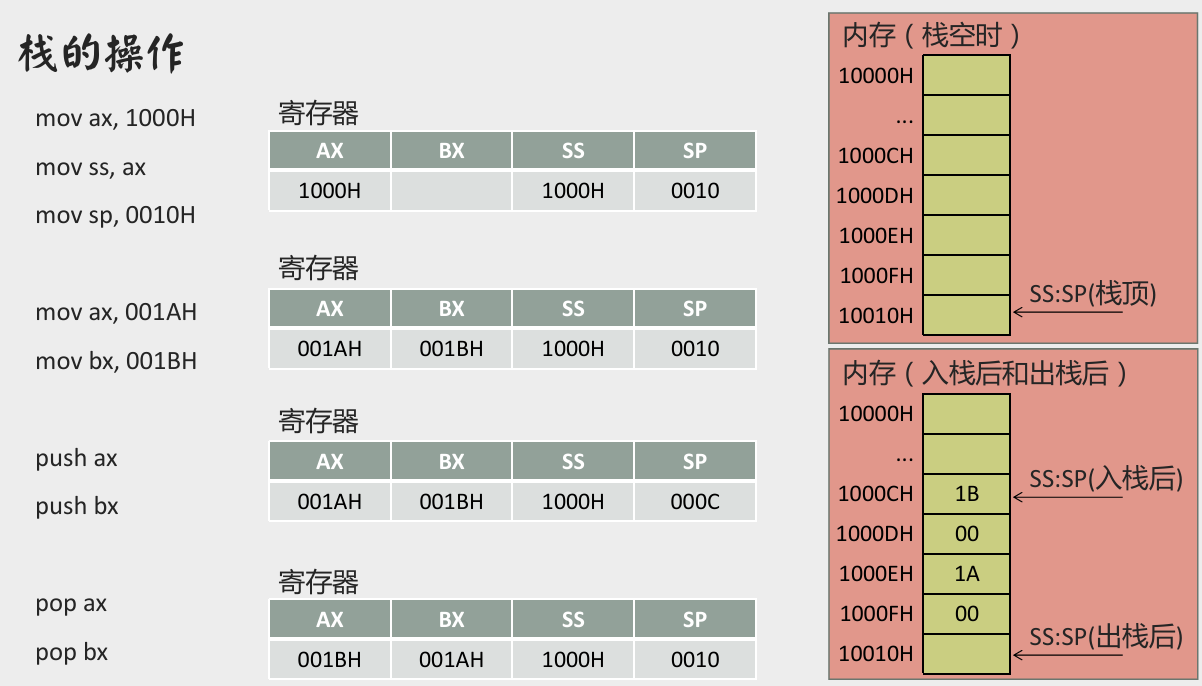
栈的操作
- 问题:
- CPU 如何知道一段内存空间被当作栈来使用?
- 执行
push和pop的时候,如何知道哪个单元是栈顶单元?
- 回答:
- 8086 CPU 中,有两个与栈相关的寄存器:
- 栈段寄存器
SS- 存放栈顶的段地址; - 栈顶指针寄存器
SP- 存放栈顶的偏移地址; - 任意时刻,
SS:SP指向栈顶元素。
- 栈段寄存器
- 8086 CPU 中,有两个与栈相关的寄存器:

栈顶超界问题的解决
- 8086 CPU 不保证对栈的操作不会超界。
- 8086 CPU 只知道栈顶在何处(由
SS:SP指示),不知道程序安排的栈空间有多大。 - 我们在编程的时候要自己操心栈顶超界的问题,要根据可能用到的最大栈空间,来安排栈的大小。
- 防止入栈的数据太多而导致的超界;
- 防止出栈时栈空了仍然继续出栈而导致的超界。
栈的小结
push、pop实质上就是一种内存传送指令,可以在寄存器和内存之间传送数据,与mov指令不同的是,push和pop指令访问的内存单元的地址不是在指令中给出的,而是由SS:SP指出的。- 执行
push和pop指令时,SP中的内容自动改变。 - 8086 CPU 提供的栈操作机制:
- 在
SS,SP中存放栈顶的段地址和偏移地址,入栈和出栈指令根据SS:SP指示的地址,按照栈的方式访问内存单元。 push指令的执行步骤:- 1)
SP=SP-2; - 2)向
SS:SP指向的字单元中送入数据。
- 1)
pop指令的执行步骤:- 1)从
SS: SP指向的字单元中读取数据; - 2)
SP=SP+2。
- 1)从
- 在

第三章 编写完整程序
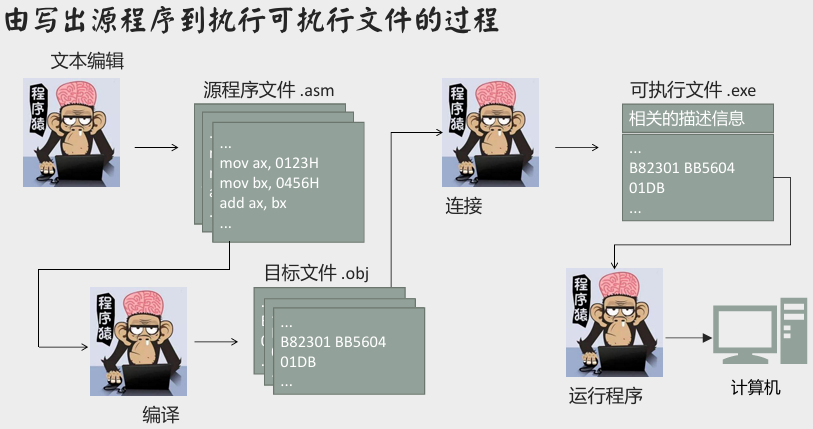
汇编语言编写程序的工作过程
- 第一步:编写汇编源程序。
- 采用文本编辑器(如 Edit、记事本等)
- 第二步:对源程序进行编译产生目标文件(存储机器码),再用连接程序对目标文件进行连接,生成可在操作系统中直接运行的可执行文件。可执行文件包含以下两部分内容:
- 程序(从源程序中的汇编指令翻译过来的机器码)和数据(源程序中定义的数据)
- 相关的描述信息(比如,程序有多大、要占用多少内存空间等)
- 第三步:执行可执行文件中的程序。
- 操作系统依照可执行文件中的描述信息,将可执行文件的机器码和数据加载入内存,并进行相关的初始化(比如设置
CS:IP指向第一条要执行的指令),然后由 CPU 执行程序。
- 操作系统依照可执行文件中的描述信息,将可执行文件的机器码和数据加载入内存,并进行相关的初始化(比如设置
源程序
- 汇编程序:包含汇编指令和伪指令的文本。
- 汇编指令:有对应机器码的指令,可以被编译为机器指令,最终为 CPU 所执行。
- 伪指令没有对应的机器指令,最终不被 CPU 所执行。伪指令是由编译器来执行的指令,编译器根据伪指令来进行相关的编译工作。
- 汇编程序示例如下:
1 | |
伪指令


源程序经编译连接后变为机器码
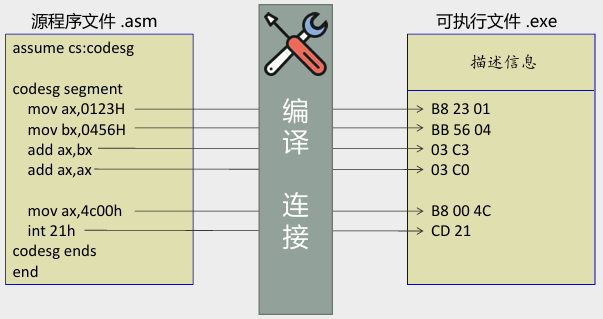
汇编程序的结构

如何写出一个汇编程序?
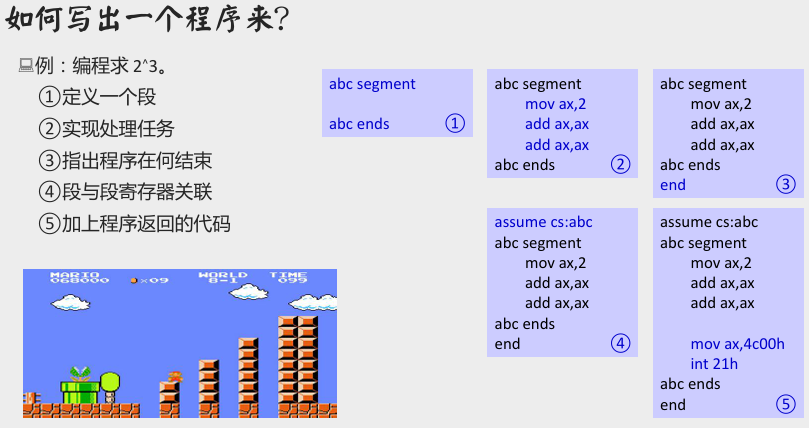
程序中可能的错误

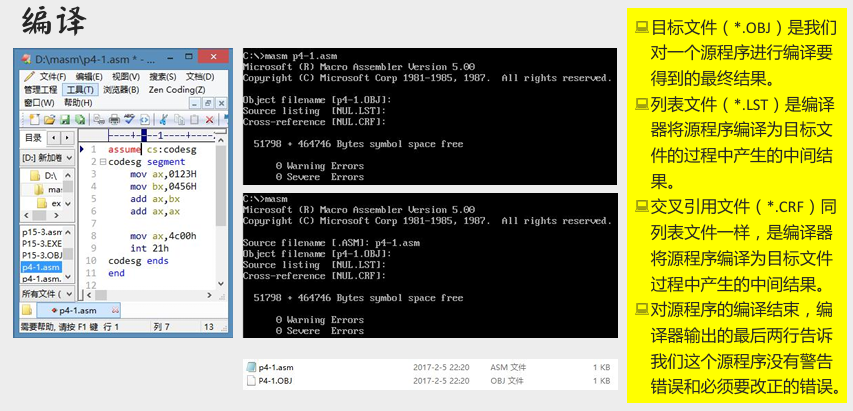
源程序到可执行文件的过程
DOS 环境的挂载
1 | |
asm 文件的编译
汇编目标文件的连接

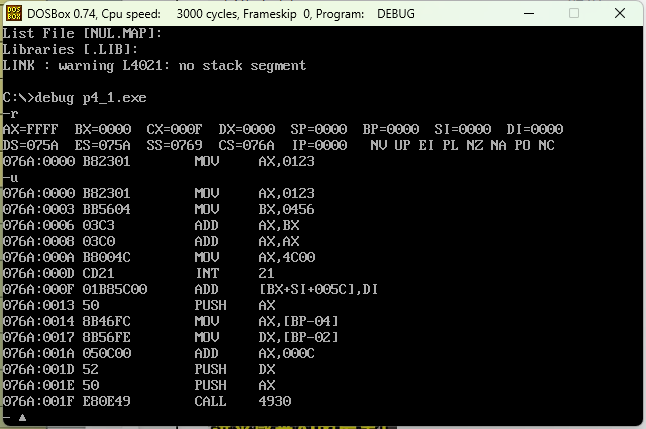
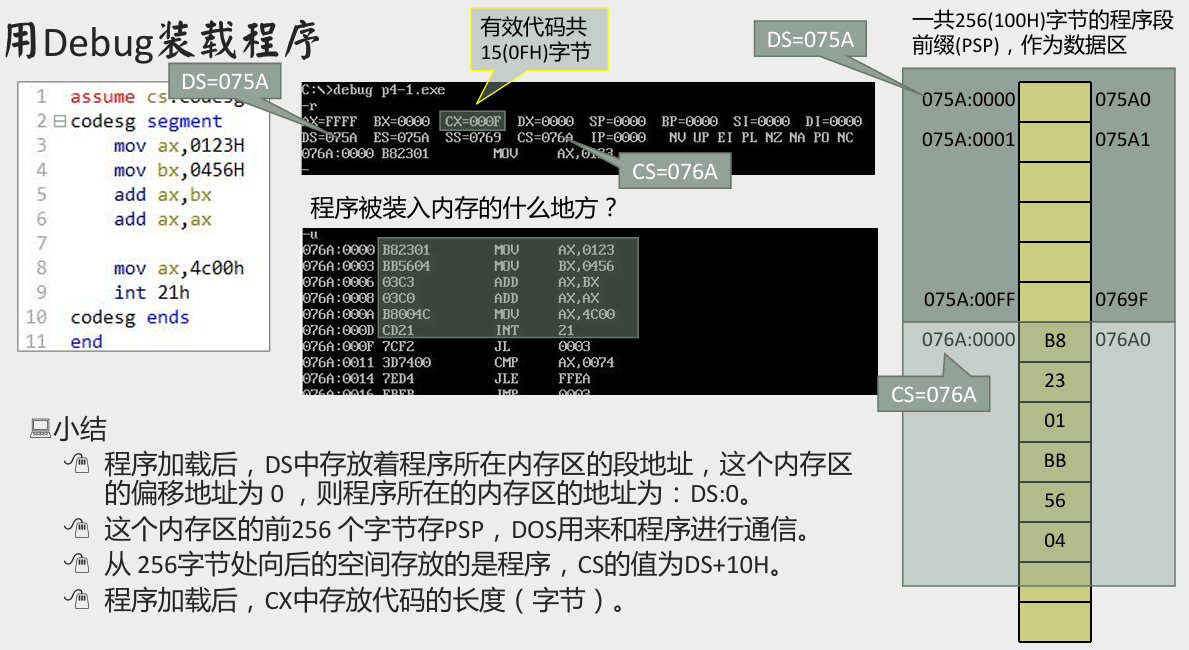
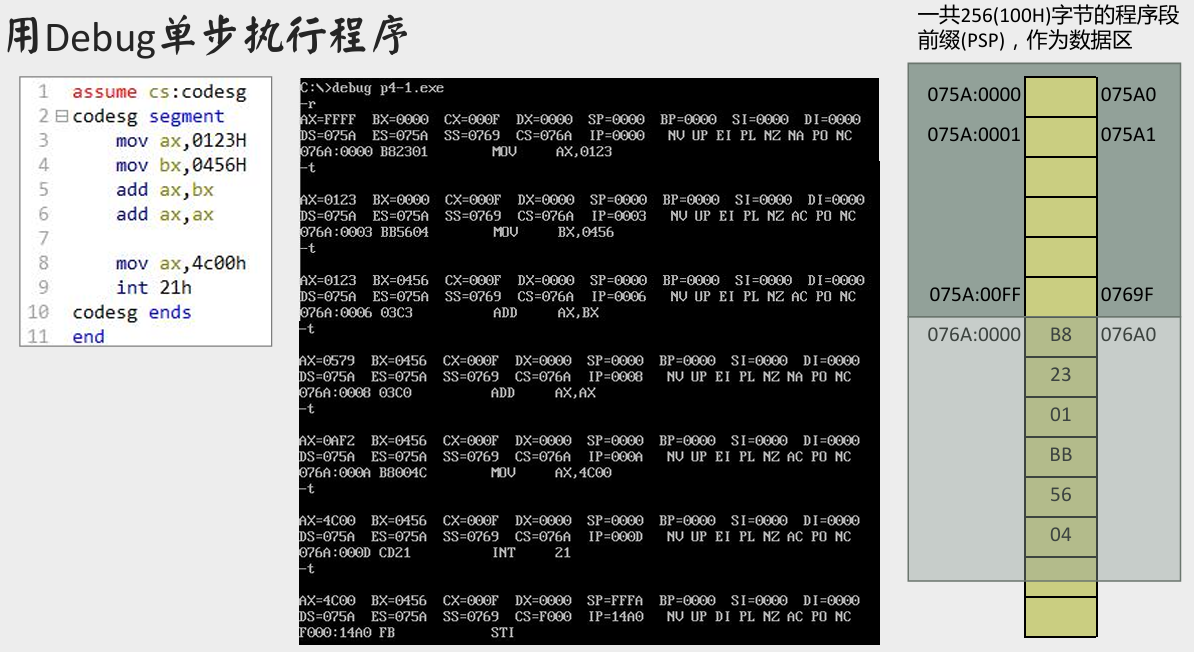
用 debug 跟踪程序执行


实验
- 将下面程序保存为
t1.asm文件,将其生成可执行文件t1.exe文件。
1 | |
- 用 debug 跟踪
t1.exe文件的执行过程,写出每一步执行后,相关寄存器中的内容和栈顶的内容。


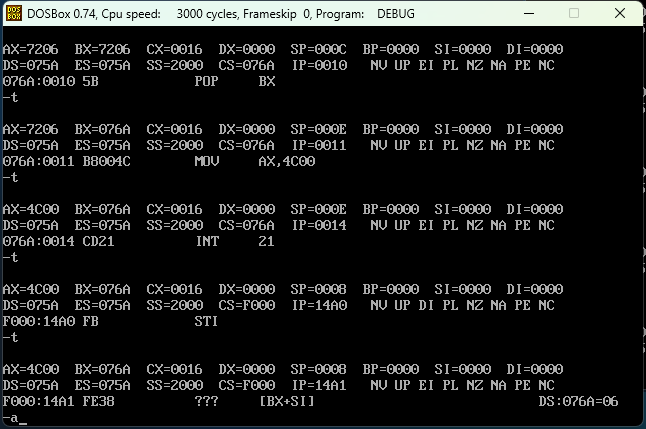
PSP的头两个字节是CD 20,用 debug 加载t1.exe文件,查看PSP的内容。
第四章 [BX]和 Loop 指令
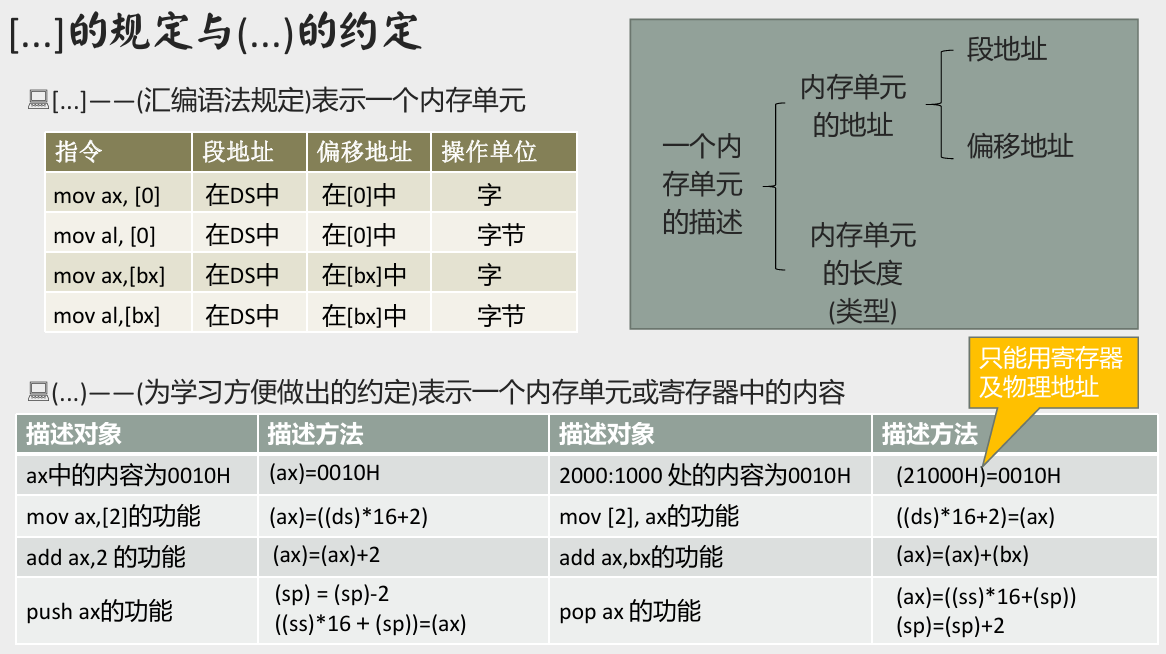
[…] 的规定与 (…) 的约定
再约定:idata 表示常量
- 例如:
mov ax,[idata]:代表mov ax,[1]、mov ax,[2]、mov ax,[3]…mov bx,idata:代表mov bx,1、mov bx,2、mov bx,3…mov ds,idata:代表mov ds,1、mov ds,2… (但都是非法指令)
Loop 指令
Loop 指令要点

Loop 指令编程实例

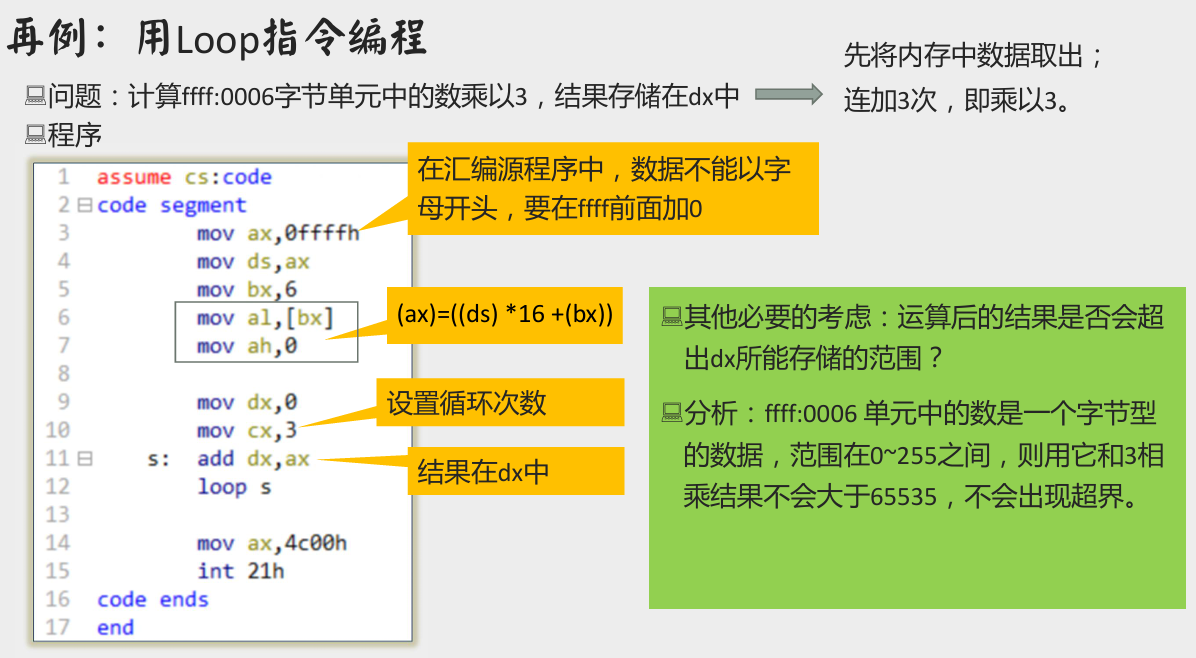
运行示例程序
Debug 执行程序

- 标号
s,用于标识地址,在程序写入内存中会直接转换为地址。

t 命令、p 命令和 g 命令的区别

段前缀
一个“异常”现象及对策
- 现象:
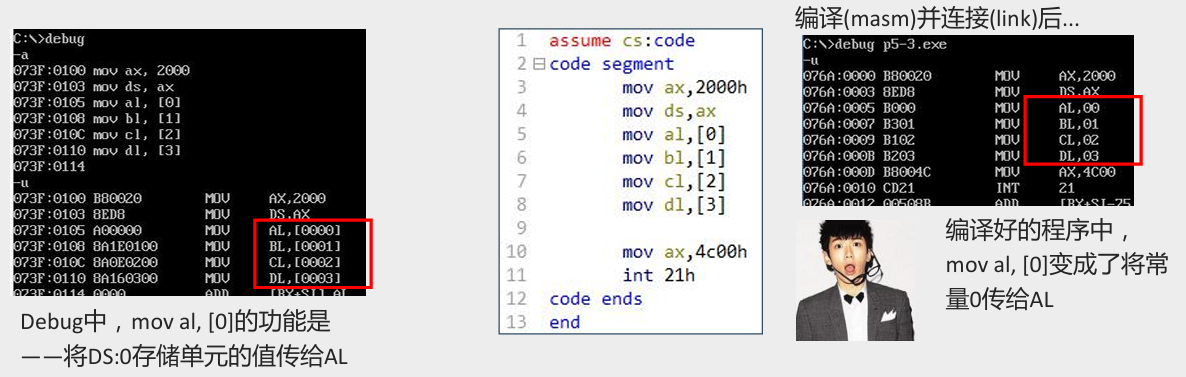
- 对策:
- 在
[idata]前显式地写上段寄存器,例mov al,ds:[bx]。
- 在

- 这些出现在访问内存单元的指令中,用于显式地指明内存单元的段地址的
ds:、cs:、ss:或es:”,在汇编语言中称为段前缀。
访问连续的内存单元 —— Loop 和 [bx] 联手
- 问题:计算
ffff:0~ffff:b字节单元中的数据的和,结果存储在dx中。 - 分析:
- 运算后的结果是否会超出
dx所能存储的范围?ffff:0~ffff:b内存单元中的数据是字节型数据,范围在0~255之间,12个这样的数据相加,结果不会大于65535,可以在dx中存放下。
- 是否可以将
ffff:0~ffff:b中的数据直接累加到dx中?add dx,ds:[addr];(dx)=(dx)+?- 期望:取出内存中的 8 位数据进行相加;实际:取出的是内存中的 16 位数据。
- 是否可以将
ffff:0~ffff:b中的数据直接累加到dl中?add dl,ds:[addr];(dl)=(dl)+?- 期望:取出内存中的 8 位数据相加;实际:取出的是内存中的 8 位数据,但很有可能造成进位丢失。
- 运算后的结果是否会超出
- 对策:取出 8 位数据,加到 16 位的寄存器
1 | |

- 代码:

段前缀的使用
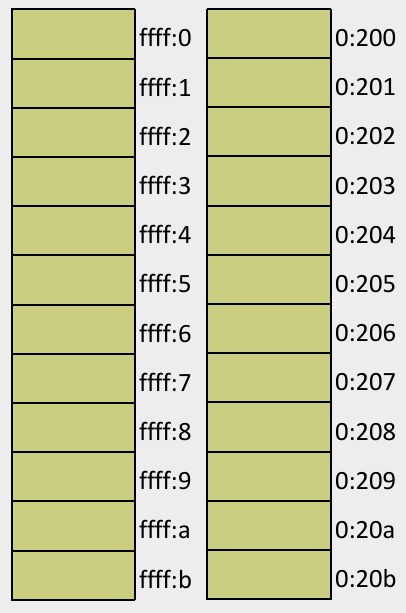
- 问题:将内存
ffff:0~ffff:b中的数据拷贝到0:200~0:20b单元中。
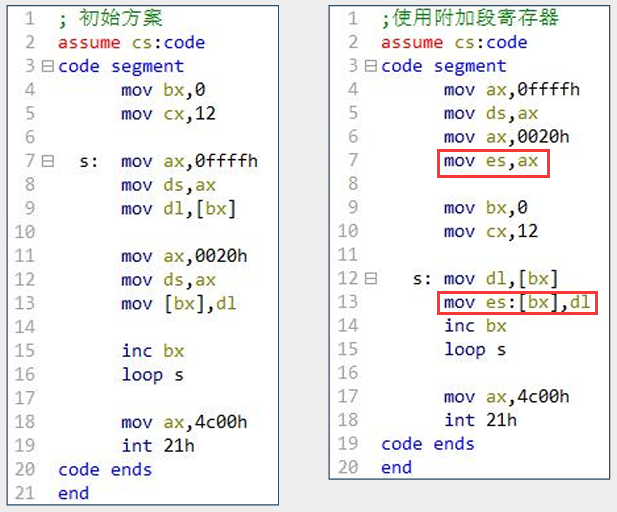
- 代码:
- 说明:
- 使用
es存放目标空间0:200~0:20b的段地址,用ds存放原始空间ffff:0~ffff:b的段地址。 - 在访问内存单元的指令
mov es:[bx],al中,显式地用附加段前缀es:给出单元的段地址,这样就不必在循环中重复设置ds。
- 使用
上述程序的问题

解决方案
- 将数据直接写在代码段中:
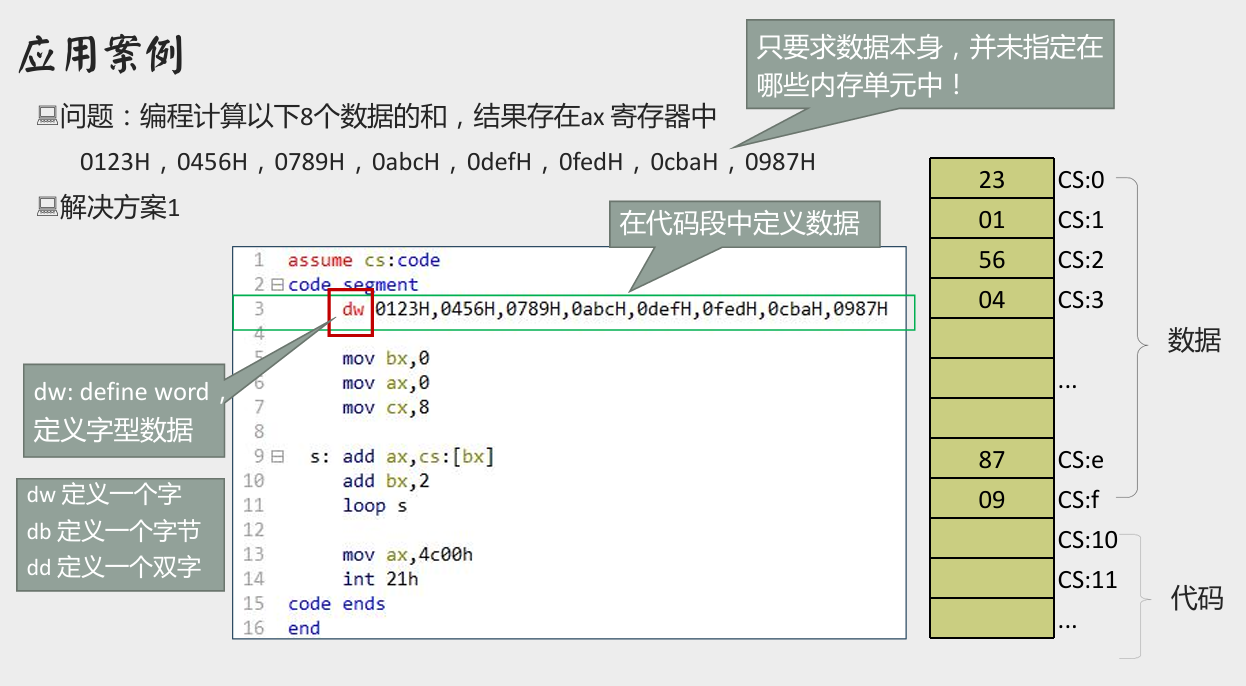
上述程序存在问题
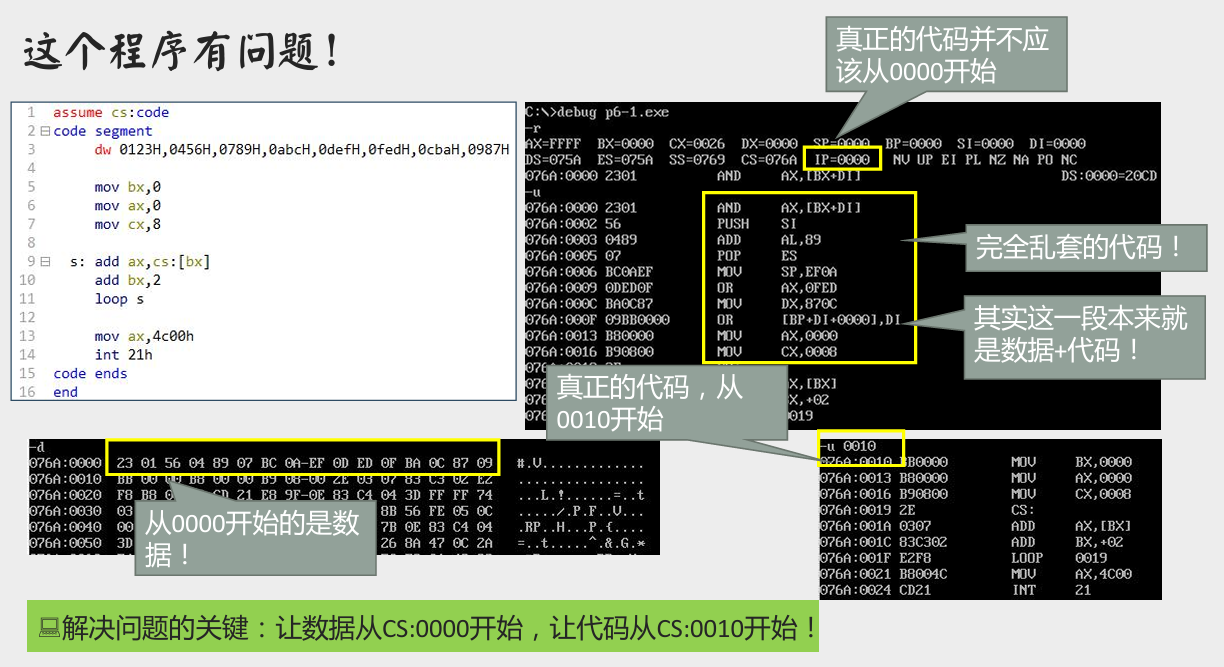
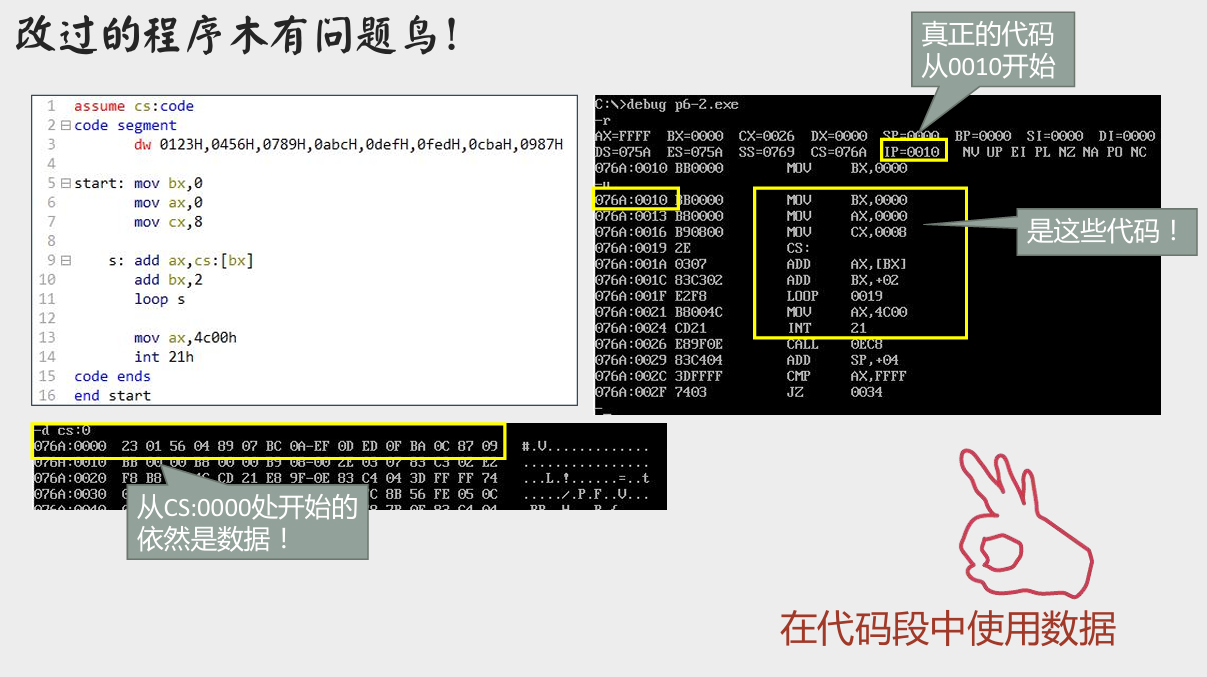
改进方案
- 定义一个标号
start,指示代码开始的位置。

实验
- 编程,向内存
0:200~0:23F依次传送数据0~63(3FH),程序中只能使用 9 条指令,包括mov ax,4c00h和int 21h。
1 | |
- 结果:
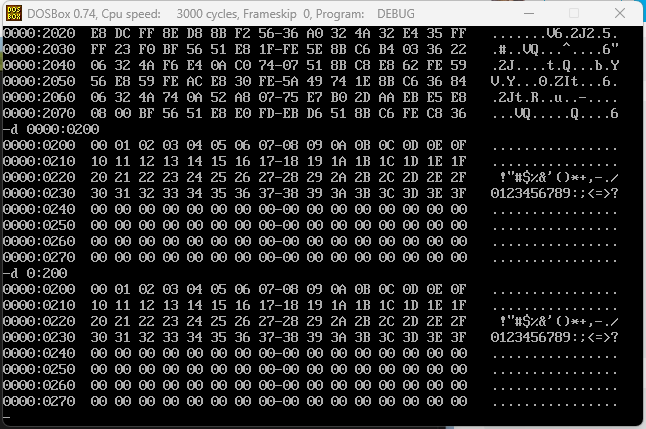
第五章 包含多个段的程序
在代码段中使用栈

数据逆序存放程序
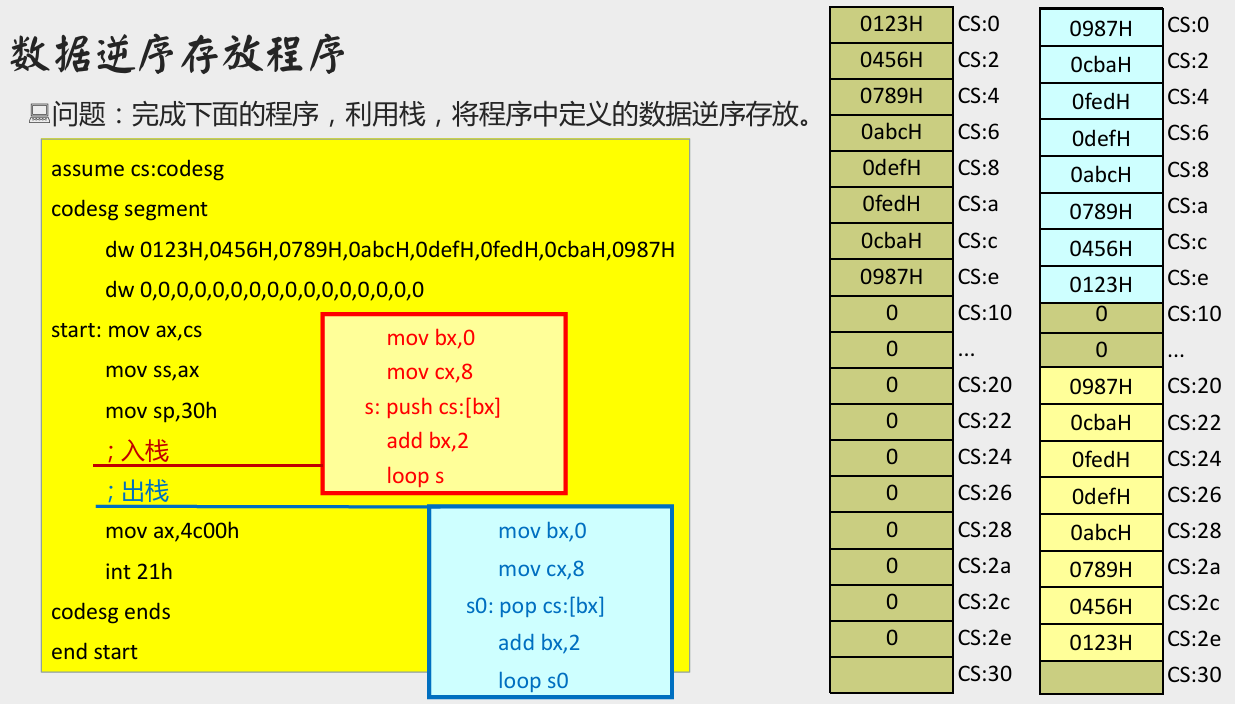
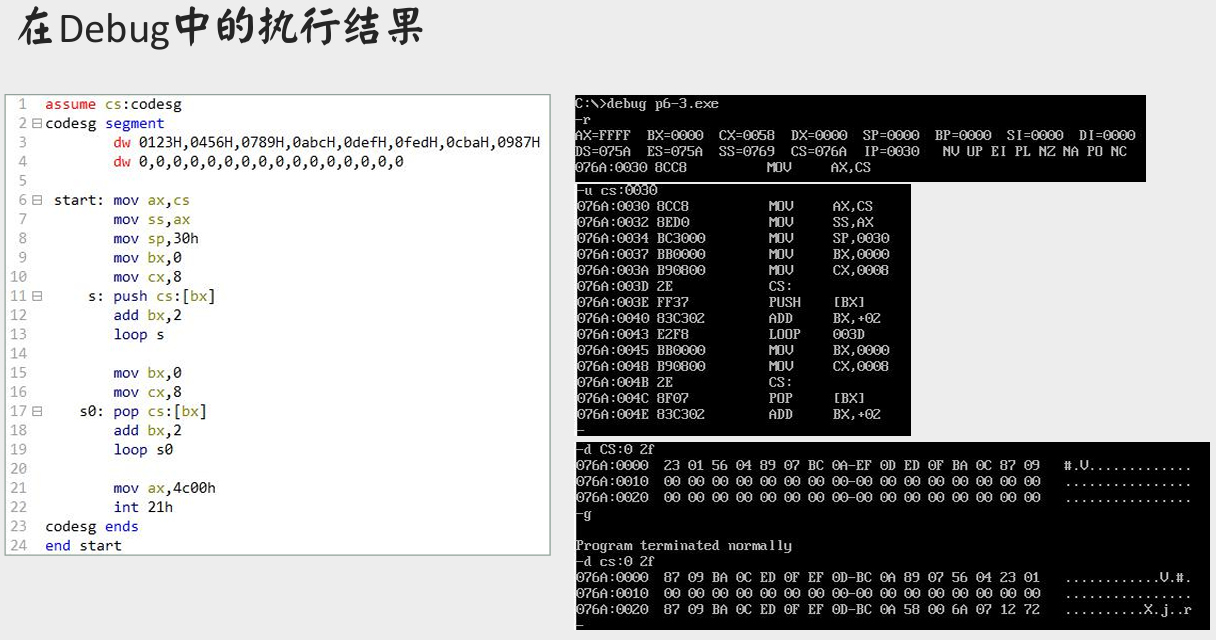
在 Debug 中的执行结果
将数据、代码、栈放入不同的段
评价上述方案
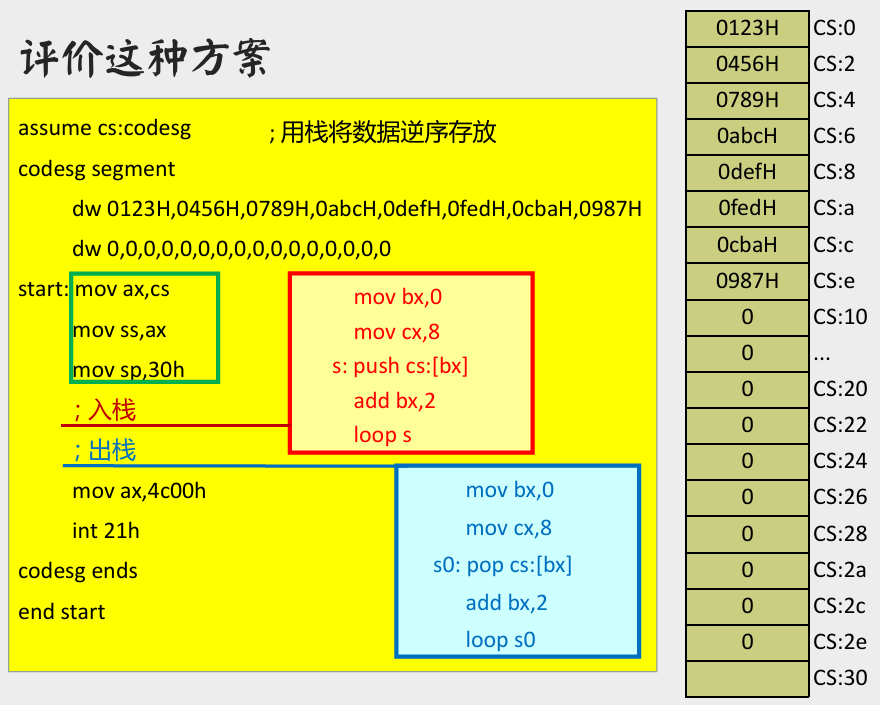
- 特点:数据、栈和代码都在一个段。
- 问题:
- 程序显得混乱,编程和阅读时都要注意何处是数据,何处是栈,何处是代码。
- 只应用于要处理的数据很少,用到的栈空间也小,加上没有多长的代码。
- 对策:数据、栈和代码放在不同段。
将数据、代码、栈放入不同的段
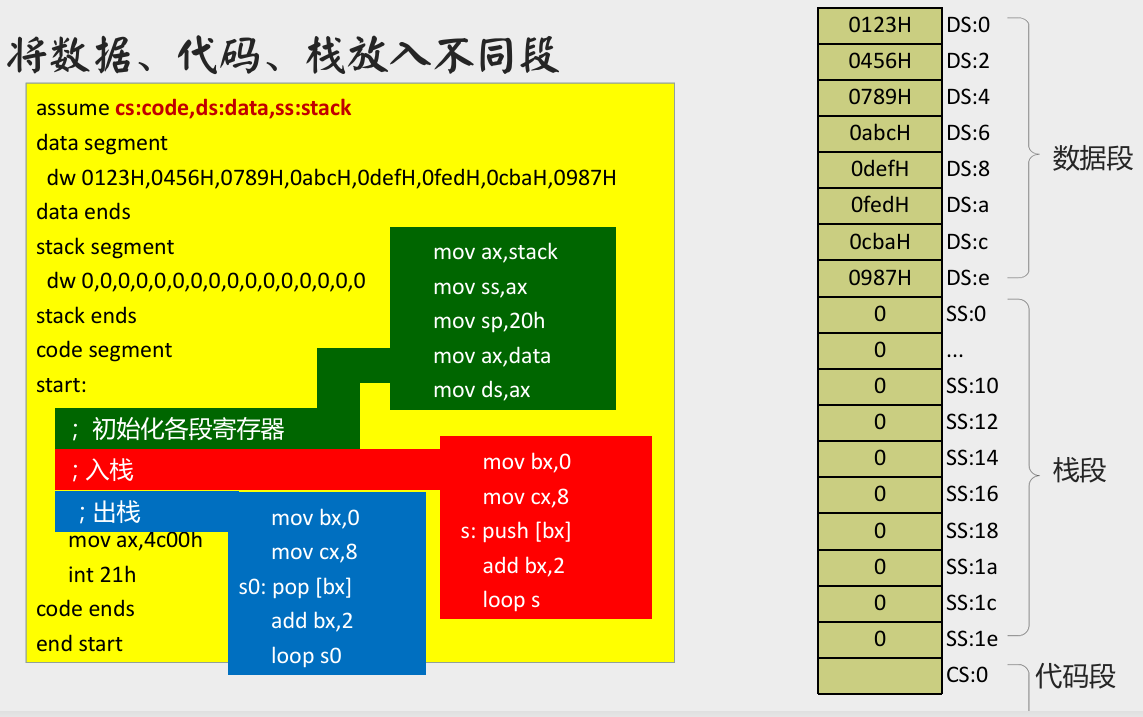
在 Debug 中的执行结果

第六章 更灵活的定位内存地址的方法
处理字符问题
- 在汇编程序中,用
'……'的方式指明数据是以字符的形式给出的,编译器将把它们转化为相对应的ASCII码。 - 代码:
1 | |
- 编译为可执行文件,并用
Debug加载查看data段中的内容:

- 说明:
- 先用
r命令分析一下data段的地址,因为DS=075A,需要加上一个256字节称为程序段前缀(PSP)的数据区,从256字节处向后的空间存放的是程序。 - 用
d命令查看data段,Debug以十六进制数码和ASCII码字符形式展示其中的内容。
- 先用

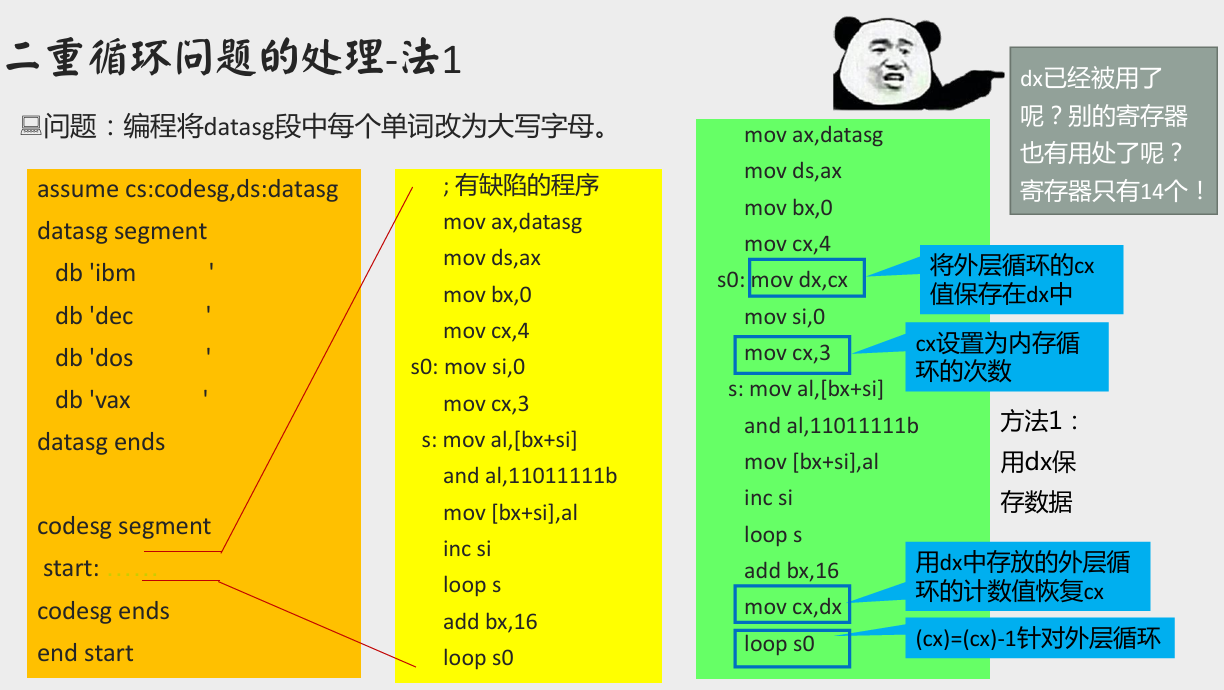
大小写转换问题

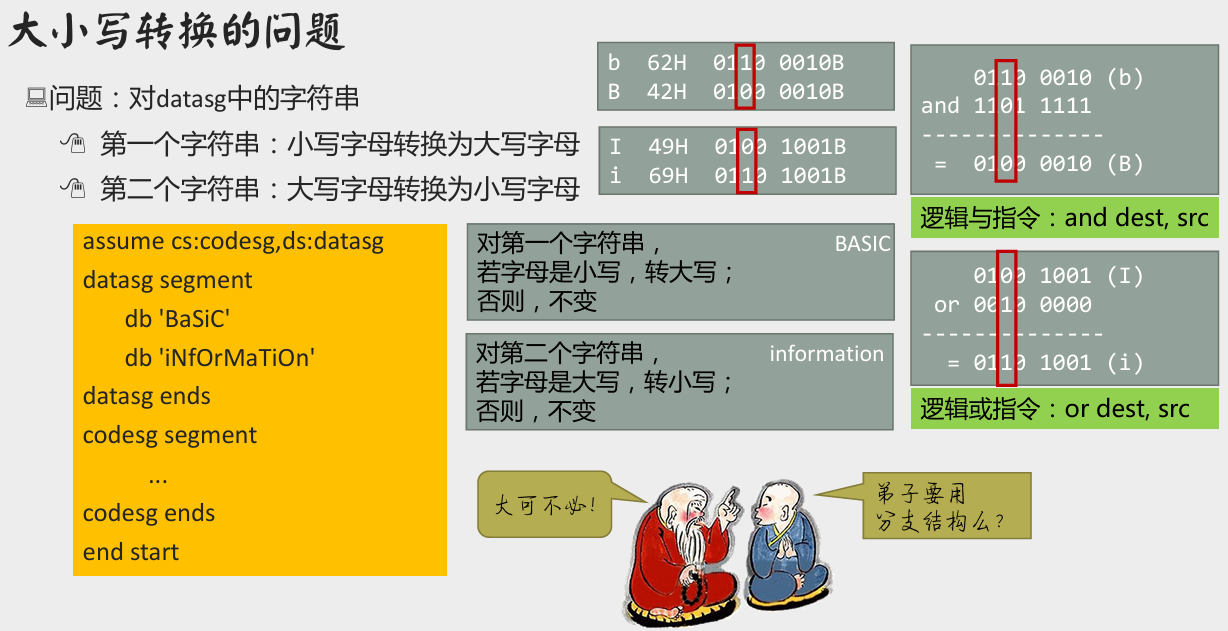
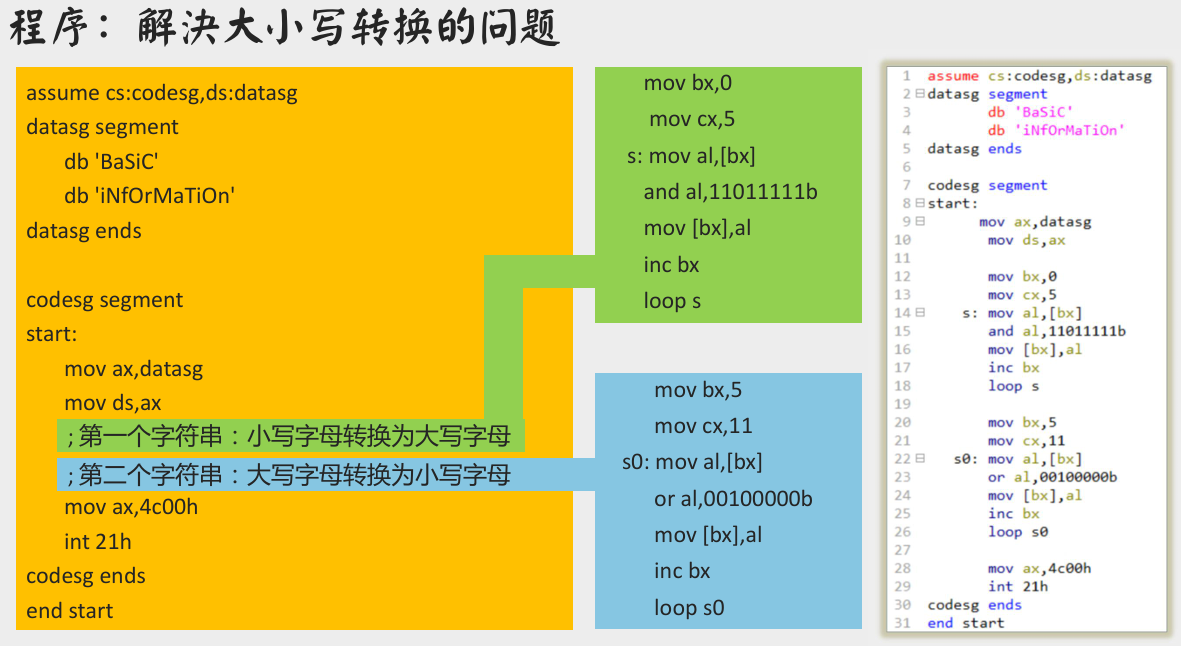
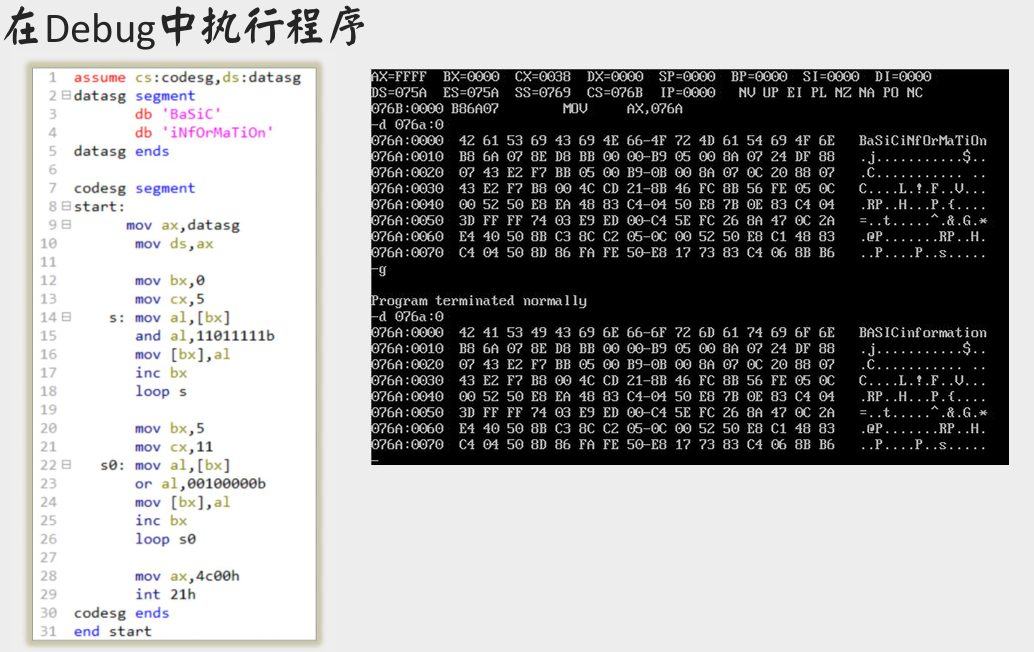
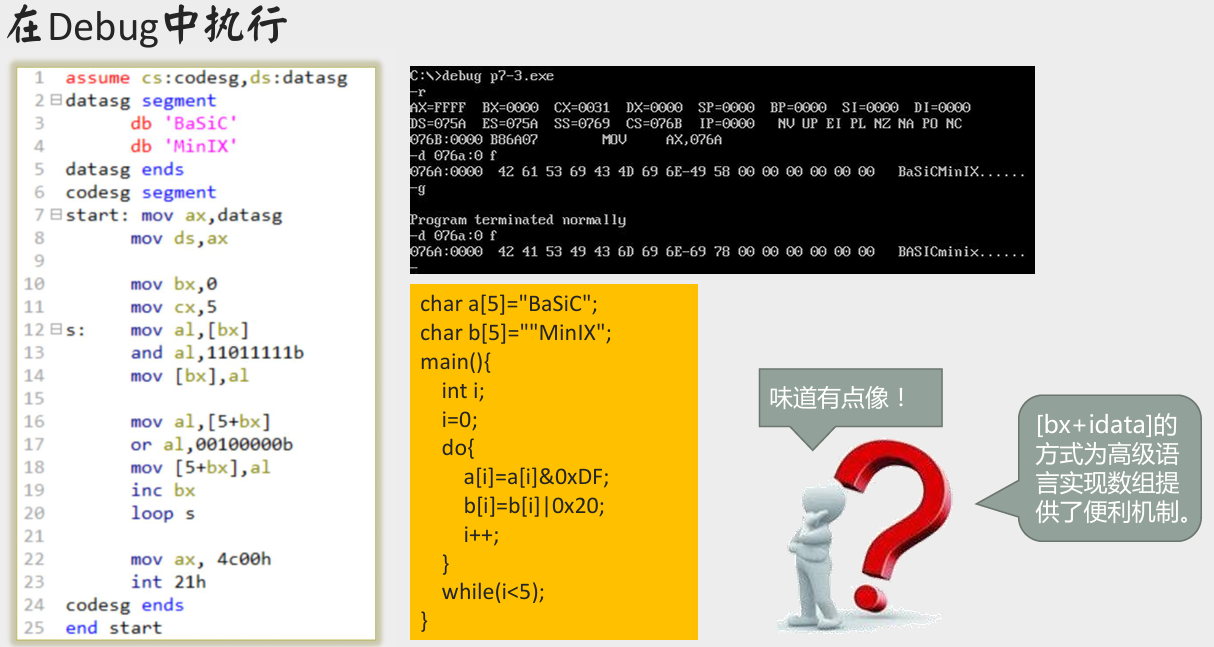
[bx+idata] 方式寻址
[bx+idata] 的含义
[bx+idata]是表示一个内存单元,它的偏移地址为(bx)+idata(bx中的数值加上idata)。mov ax,[bx+200]/mov ax, [200+bx]的含义:- 将一个内存单元的内容送入
ax, - 这个内存单元的长度为
2字节(字单元),存放一个字, - 内存单元的段地址在
ds中,偏移地址为200加上bx中的数值, - 数学化的描述为:
(ax)=((ds)*16+200+(bx));
- 将一个内存单元的内容送入
- 指令
mov ax,[bx+200]的其他写法(常用):mov ax,[200+bx],mov ax,200[bx],mov ax,[bx].200;

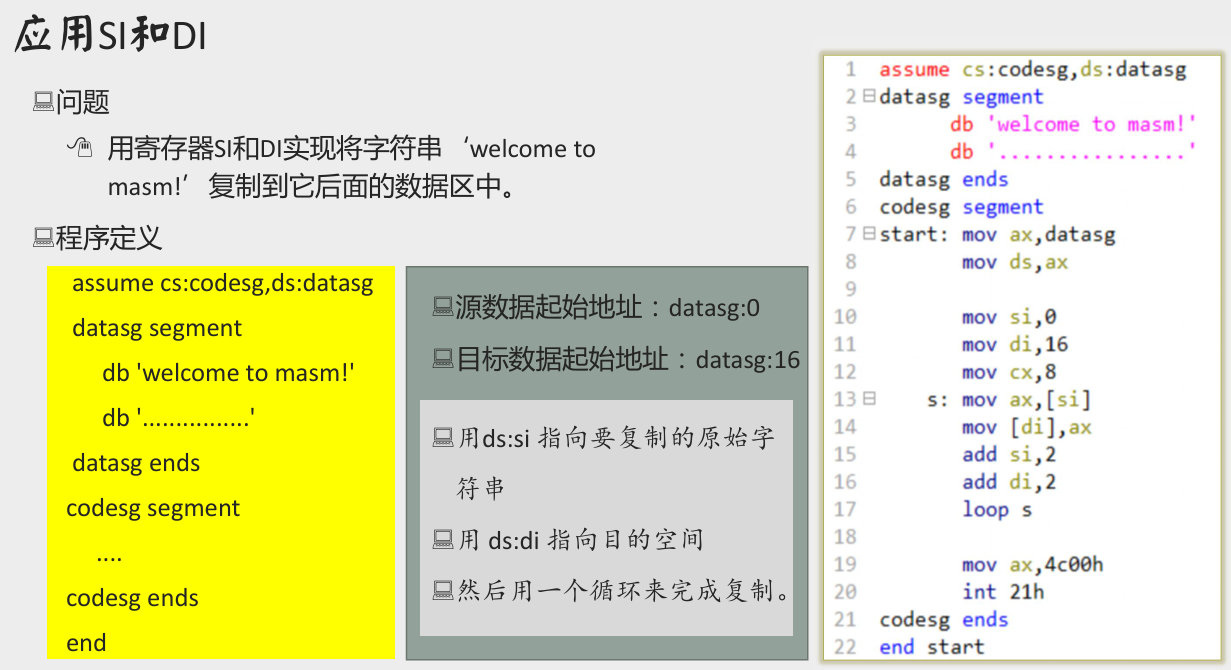
SI 寄存器和 DI 寄存器
SI 寄存器和 DI 寄存器常执行与地址有关的操作
SI寄存器和DI寄存器是 8086 CPU 中和BX功能相近的寄存器- 区别:
SI寄存器和DI寄存器不能够分成两个 8 位寄存器来使用。 BX寄存器:通用寄存器,在计算存储器地址时,常作为基址寄存器来使用,SI寄存器:source index,源变址寄存器,DI寄存器:destination index,目标变址寄存器;
- 区别:

应用


[bx+si] 和[bx+di] 方式寻址

[bx+si+idata] 和[bx+di+idata] 方式指定地址

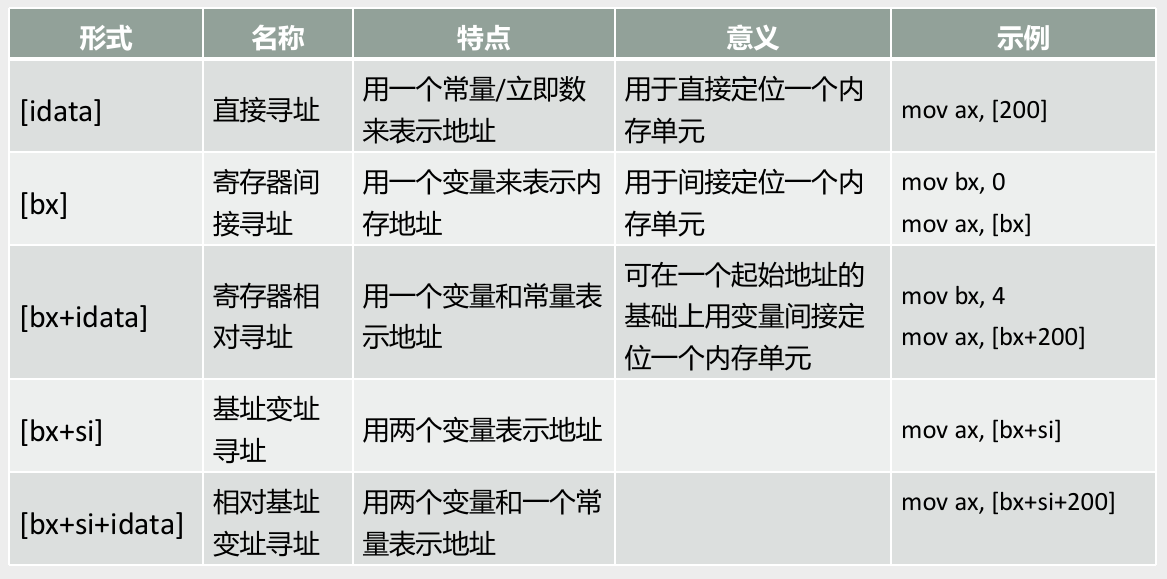
不同的寻址方式的灵活应用
对内存的寻址方式
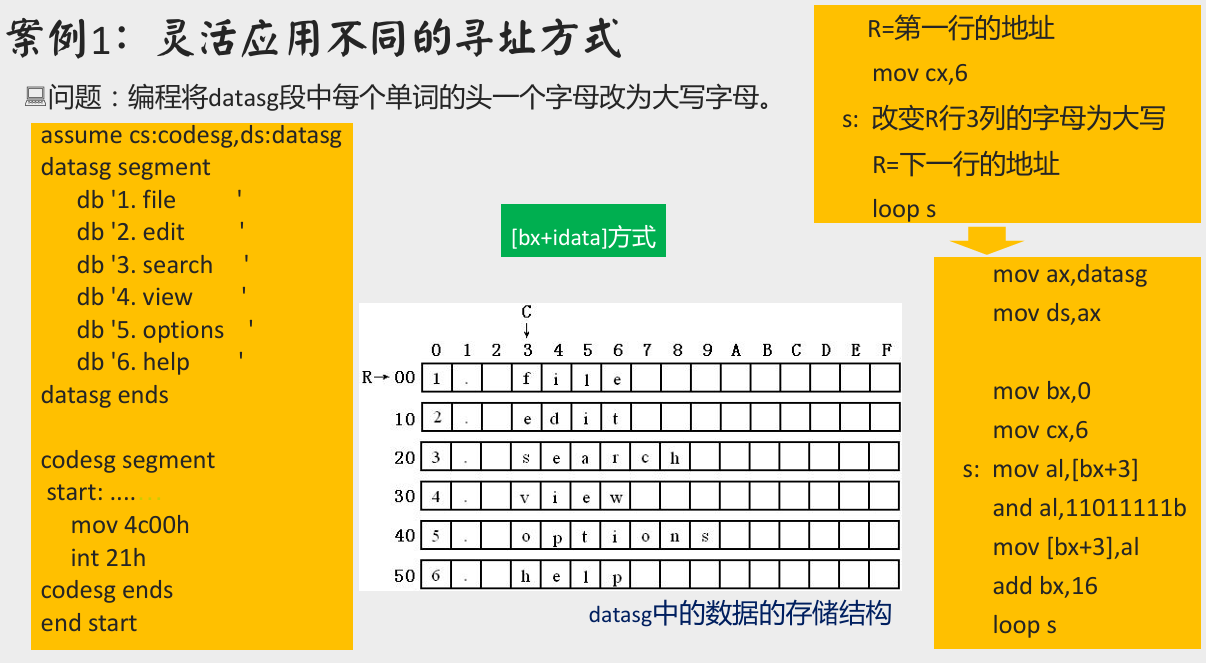
案例 1
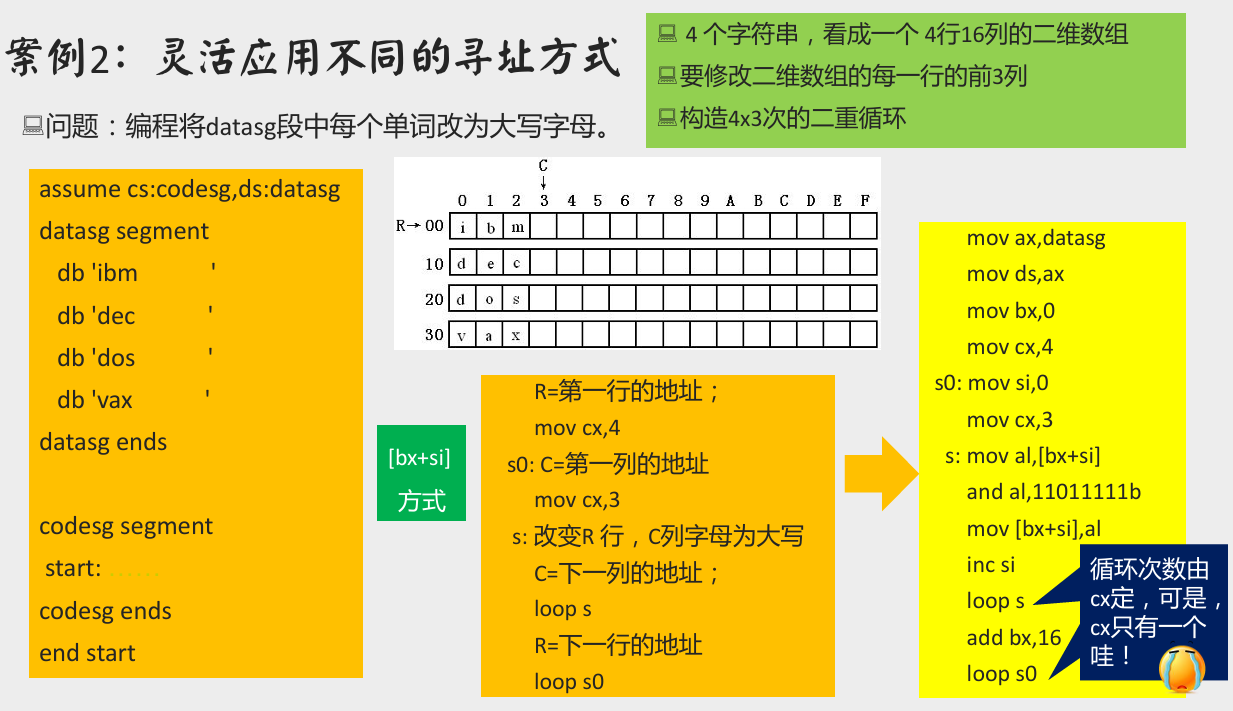
案例 2

汇编语言
http://example.com/2024/07/01/Assembly_language/