知识复习汇总2
知识复习汇总 2
项目相关
多 Agent 项目
-
什么是多智能体编排器-工作者(Orchestrator-Workers)模式?
- 借鉴了 Claude 博客中关于“如何构建高效的智能体”这篇文章,它是一种任务驱动的多智能体协作架构,其核心是由一个中央大模型(Orchestrator)动态拆解任务、分配子任务给多个工作者模型(Workers),并最终整合结果输出。
-
怎么样进行动态分块并注入来源信息,详细介绍一下分块逻辑?
- 我做的动态分块不是固定长度硬切,而是先判断文档大小:短文档(小于 1500 个字符)保留整体,长文档再按 markdown 结构递归切分,优先按标题、加粗小节、段落这些语义边界切,切不动再逐步退化到按行、按空格、按字符切,同时设置 overlap (200 个字符)保证上下文连续。
- 分块后,我会把文档来源信息直接注入到每个 chunk 的正文前缀里,而不是只放 metadata,这样 embedding 时能把来源语境一起编码进去,既提升检索召回准确率,也方便后续回答做来源溯源。最后再做 metadata 清洗和空块过滤,批量写入 Chroma。
-
为什么不用只存 metadata,不注入正文?
- 只把来源放在 metadata 里,向量化时 embedding 模型通常感知不到这些信息;
- 但把来源信息注入正文后,模型在生成向量时会把“文档标题、产品名、主题背景”一起编码进去,这对语义召回更有帮助。
- metadata 更多是给过滤和展示用,正文注入才真正作用于 embedding 表达。
-
怎么设计基于向量检索与标题分词匹配的 RAG 双路检索架构?
- 第一路是基于向量余弦距离的语义相似度检索,返回 TOP-K 个文本块,其中在项目中是 5 个。
- 第二路是标题文词匹配检索,先扫描 markdown 文件标题,再做两阶段排序:
- 第一阶段是标题粗排:用 jieba 分词 + 字符级匹配提升完整文档的召回率:
- 第一步是字符级 Jaccard 匹配,把用户问题和标题都拆成字符集合,计算交集 / 并集,这样做是因为即使 jieba 分词结果一般,字符仍然能保底召回。
- 第二步是词项级 jieba 分词匹配,对用户问题和标题做
jieba.lcut(),按词集合算 Jaccard,也就是计算交集 / 并集,相比字符级,词项级更能体现语义单元,所以权重更高。 - 其中字符级的权重是 0.3,词项级的权重是 0.7,保留前 50 个粗排结果。
- 第二阶段是标题精排:采用标题语义相似度 + 粗排分数加权:
- 分别对用户问题和粗排后的标题进行向量化,用余弦相似度算标题和问题的语义相关性,再和粗排得分做加权融合,其中粗排权重 0.3,精排权重 0.7。使得精排分数作为主导,体现语义相关性,粗排分数保留一定作用,体现关键词命中。
- 最后对长文档(大于 3000 字符)进行切分和计算分数,取 TOP-K 个标题分数的文本块,在项目中是 5 个。
- 第一阶段是标题粗排:用 jieba 分词 + 字符级匹配提升完整文档的召回率:
-
为什么要“粗排 + 精排”两阶段?
- 因为单独只用 jieba 分词会有问题:
- 只能看字面重合
- 对同义表达不够敏感
- 但如果一开始就对所有标题全量 embedding,又比较重。
- 所以我用了两阶段方案:
- 粗排负责低成本扩大召回
- 精排负责提高结果相关性
- 因为单独只用 jieba 分词会有问题:
-
标题检索为什么有意义?
- 在知识库里,很多 markdown 文档的标题本身就高度概括主题,比如“安装说明”“常见问题”“接口文档”“模型训练流程”。
- 如果只依赖 chunk 级向量检索,可能会因为切块过细导致主题信息被稀释;而标题检索等于从文档级主题入口再召回一遍,可以补足纯向量检索对文档主题感知不足的问题。
-
为什么要标题与内容前缀去重并进行相似度重排序输出前 N 个结果?
- 重复:同一文档可能既被向量检索命中,也被标题检索命中
- 分数体系不同:两条路出来的结果打分方式不完全一致
- 排序不稳定:如果不统一重排,最终结果质量会波动
- 主要步骤:
- 1、把向量和标题召回的结果合并成一个候选集
- 2、基于标题 + 内容前缀去重,把
title和content前 100 个字符组成一个联合 key 进行去重。 - 3、对去重后的候选结果做统一 embedding 相似度打分和重排序,返回 TOP-N 个文本块,在项目中是 5 个。
-
多智能体编排是使用了什么思想?
- OpenAI Agents SDK 支持两种主要的多 Agent 设计模式:Manager 模式(Agents as Tools)和Handoff 模式(交接接管)。
- Manager 模式(Agents as Tools):把子 Agent 当作工具(tool)供主 Agent 调用,控制权始终在 Manager 手里。
- Handoff 模式(交接接管):当前 Agent 把任务“交接”给另一个 Agent,由它接管后续流程。
- 我的项目中使用的是 Manager 模式(Agents as Tools),考虑到如果一个用户请求同时涉及技术判断和线下服务站查询,Manager 模式会更适合,因为主调度 Agent 可以把问题拆成两个子任务,分别交给技术专家和业务服务专家执行,再统一聚合结果。理论上既可以顺序调用,也可以并行调用。而 Handoff 模式更适合单一职责的接管场景,一旦把控制权交给某个 Agent,后续如果还需要另一个 Agent 协作,链路会变复杂,尤其不适合并行协同。
-
MCP 和 SKILL 的区别是什么?
- MCP(Model Context Protocol)是一个把外部能力接给模型的协议层。通过 MCP,模型可以连到远程 MCP server 或 connector,去访问搜索、地图、私有数据源等能力;在 OpenAI 的 Responses API 里,这些都可以通过
mcp工具类型接入。 - Skill 是一个可复用的工作流封装。它是可复用、可分享的 workflow,用来告诉 LLM 如何把某类任务做得更稳定、更一致;一个 Skill 可以打包说明、示例,甚至代码。OpenAI 也把 skills 描述成介于 prompt 和 tools 之间的“中间层”:prompt 定义常驻行为,tools 提供原子能力,skills 则把一套可重复执行的步骤封装起来。
- MCP 关注连接:把外部系统或数据源暴露给模型。Skill 关注编排:把完成某类任务的步骤、规则、资源打包成一个可复用流程。
- MCP(Model Context Protocol)是一个把外部能力接给模型的协议层。通过 MCP,模型可以连到远程 MCP server 或 connector,去访问搜索、地图、私有数据源等能力;在 OpenAI 的 Responses API 里,这些都可以通过
-
提示词的编写上有什么技巧吗?
- 1、先定义“唯一职责”,缩小模型自由度,让模型不要又当专家、又当总结器、又当调度器,避免角色混乱。
- 2、明确“工具-场景映射”,降低选错工具概率,定义工具时,不只写工具名,要写适用场景、边界和典型触发条件。
- 3、用“原则”约束行为,而不是只写功能,不只是说“怎么做”,还说了很多“不能怎么做”。
- 4、把高风险问题单独上升为“核心原则”,把最容易犯错的点,提升为显式规则,并重复强化,模型对“重复出现的关键约束”会更敏感。
- 5、把复杂任务拆成流程步骤,对多步任务,提示词最好写成 SOP,而不是一段大而泛的说明。
- 6、用正反例强化边界,提示词里最好加入“相似场景下的正反例”,帮助模型学会区分。
-
项目里的上下文工程是怎么做的?
- 持久化使用
SessionManager按用户和会话把历史消息持久化到本地 JSON 文件中; - 上下文工程则是在每轮请求时先加载历史、拼接当前输入,再通过
_truncate_memory()保留 system message、按最近 N 轮做裁剪,最后把处理后的chat_history作为Runner.run_streamed的输入传给调度 Agent,从而兼顾多轮对话连续性、token 成本和上下文质量。
- 持久化使用
-
什么是 FastAPI 的异步接口?
- FastAPI 的异步接口,指的是用
async def定义的接口函数。这里的async def表示这个接口是异步的,不会在等待大模型输出时把整个线程卡死,而是可以把等待时间让出去,去处理别的请求。
- FastAPI 的异步接口,指的是用
-
什么是 SSE 协议?
- SSE 是 Server-Sent Events,中文一般叫:服务器发送事件。
- 它是一种浏览器和服务端之间的单向流式通信协议,特点是:
- 服务端可以持续往前端推消息
- 前端不需要反复轮询
- 基于 HTTP,比较轻量
- 很适合大模型“边生成边推送”
- 资料里也明确说了,SSE 相比 WebSocket 更简单,非常适合大模型流式输出场景。
大模型相关
模型采样参数
- 在使用大模型时,会经常看到类似
Temperature这类的可配置参数,其本质是通过调整模型对 “概率分布” 的采样策略,让输出匹配具体场景需求,配置合适的参数可以提升 Agent 在特定场景的性能。 - 传统的概率分布是由 Softmax 公式计算得到的:,采样参数的本质就是在此基础上,根据不同策略“重新调整”或“截断”分布,从而改变大模型输出的下一个 token。
Temperature:温度是控制模型输出 “随机性” 与 “确定性” 的关键参数。其原理是引入温度系数 , 将 Softmax 改写为- 当 T 变小时,分布“更加陡峭”,高概率项权重进一步放大,生成更“保守”且重复率更高的文本。当 T 变大时,分布“更加平坦”,低概率项权重提升,生成更“多样”但可能出现不连贯的内容。
- 低温度(0 ⩽ Temperature < 0.3):输出更 “精准、确定”。适用场景: 事实性任务:如问答、数据计算、代码生成;严谨性场景:法律条文解读、技术文档撰写、学术概念解释等场景。
- 中温度(0.3 ⩽ Temperature < 0.7):输出 “平衡、自然”。适用场景: 日常对话:如客服交互、聊天机器人;常规创作:如邮件撰写、产品文案、简单故事创作。
- 高温度(0.7 ⩽ Temperature < 2):输出 “创新、发散”。适用场景: 创意性任务:如诗歌创作、科幻故事构思、广告 slogan brainstorm、艺术灵感启发;发散性思考。
提示词工程和上下文工程
- 提示词工程和上下文工程的区别是什么?
- 提示词工程:提示工程关注如何编写与组织 LLM 的指令以获得更优结果(例如系统提示的写法与结构化策略)
- 上下文工程:上下文工程则是在推理阶段,如何策划与维护“最优的信息集合(tokens)”,其中不仅包含提示本身,还包含其他会进入上下文窗口的一切信息。
- 为什么上下文工程重要?
- Transformer 让每个 token 能够与上下文中的所有 token 建立关联,理论上形成 (n^2) 级别的两两注意力关系。随着上下文长度增长,模型对这些两两关系的建模能力会被“拉薄”,从而自然地产生“上下文规模”与“注意力集中度”的张力。此外,模型的注意力模式来源于训练数据分布——短序列通常比长序列更常见,因此模型对“全上下文依赖”的经验更少、专门参数也更少。
- 诸如位置编码插值(position encoding interpolation)等技术可以让模型在推理时“适配”比训练期更长的序列,但会牺牲部分对 token 位置的精确理解。总体上,这些因素共同形成的是一个性能梯度,而非“悬崖式”崩溃:模型在长上下文下依旧强大,但相较短上下文,在信息检索与长程推理上的精度会有所下降。
- 怎么实现有效的上下文?
- 在“有限注意力预算”的约束下,优秀的上下文工程目标是:用尽可能少、但高信号密度的 tokens,最大化获得期望结果的概率。落实到实践中,建议围绕以下组件开展工程化建设:
- 1、系统提示(System Prompt):语言清晰、直白,信息层级把握在“刚刚好”的高度。常见两极误区:
- 过度硬编码:在提示中写入复杂、脆弱的 if-else 逻辑,长期维护成本高、易碎。
- 过于空泛:只给出宏观目标与泛化指引,缺少对期望输出的具体信号或假定了错误的“共享上下文”。建议将提示分区组织(如工具指引、输出描述等),用 XML/Markdown 分隔。无论格式如何,追求的是能完整勾勒期望行为的"最小必要信息集"(“最小"并不等于"最短”)。先用最好的模型在最小提示上试跑,再依据失败模式增补清晰的指令与示例。
- 2、工具(Tools):工具定义了智能体与信息/行动空间的契约,必须促进效率:既要返回token 友好的信息,又要鼓励高效的智能体行为。工具应当:
- 职责单一、相互低重叠,接口语义清晰;
- 对错误鲁棒;
- 入参描述明确、无歧义,充分发挥模型擅长的表达与推理能力。常见失败模式是“臃肿工具集”:功能边界模糊,导致“选哪个工具”这一决策本身就含混不清。如果人类工程师都说不准用哪个工具,别指望智能体做得更好。精心甄别一个“最小可行工具集(MVTS)”往往能显著提升长期交互中的稳定性与可维护性。
- 3、示例(Few-shot):始终推荐提供示例,但不建议把“所有边界条件”的罗列一股脑塞进提示。请精挑细选一组多样且典型的示例,直接画像“期望行为”。对 LLM 而言,好的示例胜过千言万语。
- 面向长时程任务的上下文工程?
- 长时程任务要求智能体在超出上下文窗口的长序列行动中,仍能保持连贯性、上下文一致与目标导向。例如大型代码库迁移、跨数小时的系统性研究。指望无限增大上下文窗口并不能根治“上下文污染”与相关性退化的问题,因此需要直接面向这些约束的工程手段:压缩整合(Compaction)、结构化笔记(Structured note-taking)与子代理架构(Sub-agent architectures)。
- 1、压缩整合(Compaction)
- 定义:当对话接近上下文上限时,对其进行高保真总结,并用该摘要重启一个新的上下文窗口,以维持长程连贯性。
- 实践:让模型压缩并保留架构性决策、未解决缺陷、实现细节,丢弃重复的工具输出与噪声;新窗口携带压缩摘要 + 最近少量高相关工件(如“最近访问的若干文件”)。
- 调参建议:先优化召回(确保不遗漏关键信息),再优化精确度(剔除冗余内容);一种安全的“轻触式”压缩是对“深历史中的工具调用与结果”进行清理。
- 2、结构化笔记(Structured note-taking)
- 定义:也称“智能体记忆”。智能体以固定频率将关键信息写入上下文外的持久化存储,在后续阶段按需拉回。
- 价值:以极低的上下文开销维持持久状态与依赖关系。例如维护 TODO 列表、项目 NOTES.md、关键结论/依赖/阻塞项的索引,跨数十次工具调用与多轮上下文重置仍能保持进度与一致性。
- 说明:在非编码场景中同样有效(如长期策略性任务、游戏/仿真中的目标管理与统计计数)。结合 MemoryTool,可轻松实现文件式/向量式的外部记忆并在运行时检索。
- 3、子代理架构(Sub-agent architectures)
- 思想:由主代理负责高层规划与综合,多个专长子代理在“干净的上下文窗口”中各自深挖、调用工具并探索,最后仅回传凝练摘要(常见 1,000–2,000 tokens)。
- 好处:实现关注点分离。庞杂的搜索上下文留在子代理内部,主代理专注于整合与推理;适合需要并行探索的复杂研究/分析任务。
- 经验:公开的多智能体研究系统显示,该模式在复杂研究任务上相较单代理基线具有显著优势。
- 总结:
- 压缩整合:适合需要长对话连续性的任务,强调上下文的“接力”。
- 结构化笔记:适合有里程碑/阶段性成果的迭代式开发与研究。
- 子代理架构:适合复杂研究与分析,能从并行探索中获益。
Agent 开发相关
Agent 核心概念
- 对于不同的场景应该分别选什么模型?
- 推理模型的代价是延迟更高、token 消耗更大,所以不是所有场景都适合用。一个常见的工程做法是:用推理能力强的大模型做核心决策(比如任务规划、关键判断),用更快更便宜的小模型做简单任务(比如意图分类、格式提取),根据不同环节的需求来搭配。
- 什么是 Harness Engineering(驾驭工程)?它和传统 Prompt Engineering 有什么本质区别?
- Harness Engineering 是 2025 年兴起的一个概念,指的是系统性地设计、约束和引导 AI Agent 行为的工程实践,它超越了单纯的 Prompt Engineering,涵盖了从系统架构、工具编排、安全护栏到反馈回路的全链路设计。
- 与 Prompt Engineering 的区别:
• Prompt Engineering:聚焦于“如何写好一段提示词”,让 LLM 给出更好的单次回答
• Harness Engineering:聚焦于“如何构建一套系统”,让 Agent 在复杂环境中持续、安全、可控地工作 - Harness Engineering 的核心要素包括:
- 行为约束:定义 Agent 的行为边界和安全护栏
- 工具编排:设计 Agent 可用的工具集和调用策略
- 反馈回路:建立 Agent 行为的监控、评估和修正机制
- 上下文管理:动态管理 Agent 的记忆和上下文窗口
- 人机协作:设计合理的 Human-in-the-Loop 交互点
- 简单来说,Prompt Engineering 是“调教一个模型”,Harness Engineering 是“驾驭一个系统”。
三个单智能体范式
- ReAct: 我们构建了一个能与外部世界交互的 ReAct 智能体。通过“思考-行动-观察”的动态循环,它成功地利用搜索引擎回答了自身知识库无法覆盖的实时性问题。其核心优势在于环境适应性和动态纠错能力,使其成为处理探索性、需要外部工具输入的任务的首选。
- Plan-and-Solve: 我们实现了一个先规划后执行的 Plan-and-Solve 智能体,并利用它解决了需要多步推理的数学应用题。它将复杂的任务分解为清晰的步骤,然后逐一执行。其核心优势在于结构性和稳定性,特别适合处理逻辑路径确定、内部推理密集的任务。
- Reflection (自我反思与迭代): 我们构建了一个具备自我优化能力的 Reflection 智能体。通过引入“执行-反思-优化”的迭代循环,它成功地将一个效率较低的初始代码方案,优化为了一个算法上更优的高性能版本。其核心价值在于能显著提升解决方案的质量,适用于对结果的准确性和可靠性有极高要求的场景。

- 这三种范式在"思考"与"行动"的组织方式上有什么本质区别?
- ReAct:思考和行动交替耦合
- Plan-and-Solve:思考先于行动,属于先规划后执行
- Reflection:行动后再思考,属于先尝试后修正
- 如果把它们看成三种“智能体时间结构”:
- ReAct 关注“当前下一步怎么做”
- Plan-and-Solve 关注“整个任务应该怎么分解”
- Reflection 关注“刚才做得对不对,怎么改进”
OpenClaw 架构
架构
- OpenClaw 的核心秘密只有一个:一切皆 Markdown。 没有模型微调,没有复杂的提示词编译器,没有黑盒——一组精心设计的 Markdown 文件在每次对话时被动态组装成系统提示词,赋予 AI 助手人格、记忆、技能和行为准则。
认知层
- OpenClaw 的提示词系统由一组放置在工作区目录下的 Markdown 文件组成,每个文件承担特定职责,共同构成 Agent 的完整”人格架构”。系统在每次 Agent 运行时扫描工作区(大小写不敏感),将这些文件注入系统提示词的 # Project Context 区域。
1 | |
- SOUL.md 是最核心的文件,定义了 Agent 的人格与价值观,赋予智能体灵魂。它的设计哲学鲜明地反对”讨好型 AI”——开篇即声明:“Be genuinely helpful, not performatively helpful. Skip the ‘Great question!’ and ‘I’d be happy to help!’ — just help.” 该文件允许 Agent 拥有自己的观点(”You’re allowed to disagree, prefer things, find stuff amusing or boring”),建立了”内部行为大胆、外部行为谨慎”的信任模型——读取文件、搜索信息可以自由执行,但发送邮件、发推文等外部行为必须谨慎确认。SOUL.md 的最后一行尤为精妙:“This file is yours to evolve. As you learn who you are, update it.” ——Agent 被允许修改自己的”灵魂”,但必须告知用户。也就是说,随着和用户的交互,智能体的灵魂会随之成长和发展!
- AGENTS.md 是最全面的”操作手册”,包含会话启动流程、记忆系统规则、安全边界、群聊行为准则、工具使用指引和心跳(Heartbeat)任务规范。其中群聊行为规则堪称亮点:“Humans in group chats don’t respond to every single message. Neither should you.” 它指导 Agent 在被@提及时回复、在有真正价值可贡献时发言,但在闲聊或已有人回答时保持沉默。AGENTS.md 还定义了记忆的核心原则——**“Text > Brain ”(**好记性不如烂笔头),即任何需要记住的东西必须写入文件,因为”心理笔记(session memory)无法在会话重启后存活”。
- IDENTITY.md 存储 Agent 的自选身份(名称、生物类型、风格、签名 emoji),由 Agent 在首次对话中自主填写。
- USER.md 存储用户信息(姓名、时区、偏好),随时间逐步丰富,但明确警告”你在了解一个人,不是在建档案”。
- TOOLS.md 存放用户特有的环境信息(摄像头名称、SSH 主机、TTS 偏好),实现了技能定义与环境配置的分离——技能可以共享,但你的基础设施信息只属于你。
- HEARTBEAT.md 是一个可编辑的轻量任务清单,控制 Agent 在定期心跳检查时做什么。
- BOOTSTRAP.md 是一次性的”诞生仪式”脚本,引导 Agent 通过对话发现自己的身份,然后自我删除。
- 每个文件都有字符上限(默认 20,000 字符,代码级默认 65,536),超限时按 70% 头部 + 20% 尾部 + 10% 截断标记 的比例截断。空白文件被跳过,缺失文件会注入一行缺失标记。子 Agent 会话仅注入 AGENTS.md 和 TOOLS.md,大幅减少 prompt 体积。
从用户消息到 LLM 调用的完整流水线
- OpenClaw 的提示词组装是一个精密的三阶段流水线,由
src/agents/目录下的 system-prompt.ts 代码实现。理解这个流程是理解整个系统的关键。 - 第一阶段:运行时参数收集。
buildSystemPromptParams()函数(位于 system-prompt-params.ts)负责收集所有运行时上下文:主机名、操作系统、CPU 架构、Node 版本、当前模型、频道类型、频道能力(如inlineButtons)、思维模式(thinking level)、Agent ID、工作区路径等。 - 第二阶段:系统提示词组装。 这是核心所在。buildAgentSystemPrompt 函数接收参数对象,按严格顺序拼接以下区段:
- 基础身份:”You are a personal assistant running inside OpenClaw.”
- 工具列表(Tooling):按固定顺序列出所有可用工具及一行描述。工具经过六层策略过滤(工具配置文件 → 提供商策略 → 全局允许/拒绝 → Agent 策略 → 群组策略 → 沙箱策略)。
- 工具调用风格:默认不解说常规操作,仅在多步骤任务、复杂问题或敏感操作时解说。
- 安全护栏:简短的咨询性提醒,提示避免权力寻求行为。注意这只是建议性的——真正的安全由工具策略、执行审批和沙箱强制执行。
- 技能列表(仅
full模式):XML 格式的可用技能元数据,包含名称、描述和文件路径。 - 记忆召回指令(仅当
memory_search/memory_get工具可用时)。 - 自更新指令、模型别名、工作区路径、文档引用。
- 沙箱信息(启用时):沙箱路径、挂载模式、浏览器桥接 URL、noVNC 地址。
- 当前日期时间:仅包含时区,不包含动态时间——这是一个精妙的缓存优化设计,确保 Anthropic 的 prompt 缓存命中率最大化。Agent 需要当前时间时通过
session_status工具获取。 - 回复标签、消息路由、语音/TTS、额外系统提示词。
- 反应(Reactions)指令:按频道类型定制 emoji 反应行为。
- 静默回复(
SILENT_REPLY)和心跳确认(HEARTBEAT_OK)协议。 - 运行时信息行:一行式摘要(
agent=main | host=mbp | os=darwin | model=claude-sonnet-4-5 | channel=telegram)。 - 推理模式:当前可见性级别和切换提示。
- 项目上下文(Bootstrap 文件注入):所有工作区 Markdown 文件的内容。
- 第三阶段:注入 Agent 会话。
buildEmbeddedSystemPrompt()包装组装结果,通过createSystemPromptOverride()生成覆盖函数,在createAgentSession()时替换 pi-coding-agent 的默认 prompt。整个过程确保 OpenClaw 完全控制发送给 LLM 的系统提示词。
三种提示词模式与上下文压缩策略
- OpenClaw 通过提示词模式分层 和 自动压缩 两套机制管理上下文窗口——这是长对话场景下最关键的工程挑战。
- Prompt 模式在运行时自动确定(非用户配置)。
full模式包含所有区段,用于主 Agent 和用户直接对话;minimal模式用于通过sessions_spawn生成的子 Agent,省略了约 60% 的 prompt 内容(去掉技能列表、记忆召回、自更新、用户身份、回复标签、消息路由、TTS、静默回复和心跳),仅保留工具定义、安全规则、工作区路径、沙箱信息和运行时信息。额外注入的提示词在子 Agent 上下文中被标记为 “Subagent Context” 而非 “Group Chat Context”。none模式仅返回基础身份行,预留给极简场景。 - 上下文压缩(Compaction) 在两种情况下触发:一是模型返回上下文溢出错误时自动压缩并重试;二是成功完成一轮对话后,当已使用 token 超过
contextWindow - reserveTokens时主动压缩。默认预留缓冲区为 20,000 token。压缩过程将旧对话历史总结为紧凑摘要,保留近期消息完整,摘要持久化在会话 JSONL 文件中。 - 最精妙的设计是压缩前的记忆刷写(Pre-Compaction Memory Flush)。 在上下文即将被压缩前,OpenClaw 自动触发一个静默的 Agent 回合,提示词为:“Session nearing compaction. Store durable memories now.”,要求模型将重要信息写入
memory/YYYY-MM-DD.md,如果没有需要保存的内容则回复NO_REPLY。这个机制确保了压缩不会造成认知丢失——可以类比为”认知虚拟内存”系统,上下文是 RAM,磁盘文件是持久存储,压缩前自动 flush dirty page。 - 此外,会话修剪(Session Pruning) 作为独立于压缩的优化机制,在每次 LLM 调用前裁剪旧的工具调用结果(不修改磁盘上的 JSONL 文件),采用
cache-ttl模式在 Anthropic 上一次调用超过 TTL 时清理,通过软裁剪(保留头尾)或硬清除(替换为占位符)处理超大结果。
按需加载的技能系统与混合检索记忆
- OpenClaw 的技能和记忆系统体现了同一设计哲学:提示词中只放元数据,内容按需加载。
- 技能系统遵循”即时加载”(Just-in-Time Loading)原则。系统提示词中仅注入技能的名称、描述和文件路径(XML 格式),而不预加载任何 SKILL.md 的完整内容。模型在判断需要使用某个技能时,通过
read工具读取对应的 SKILL.md。规则明确:如果恰好一个技能适用就读取它;如果多个可能适用就选最具体的一个;如果没有适用的就不读取任何技能文件。这将基础 prompt 保持在约 2.7 k-10 k token(取决于 bootstrap 文件大小),而 ClawHub 上已有超过 5,700 个社区构建的技能。 技能从四个目录按优先级加载:工作区skills/(最高)、~/.openclaw/skills/(管理级)、内置技能、额外配置目录。技能发现使用缓存快照避免冗余文件扫描。 - 记忆系统采用扁平 Markdown 文件作为唯一真相来源(single source of truth),上层建立混合检索索引。两层架构包括:
MEMORY.md(长期记忆,仅在私人会话中加载,安全隔离群聊)和memory/YYYY-MM-DD.md(每日追加日志)。检索通过 SQLite 数据库实现 BM 25 关键词搜索 + 向量语义搜索 的混合模式,使用 SQLite-vec 加速,嵌入模型支持 OpenAItext-embedding-3-small、Geminitext-embedding-004或本地 node-llama-cpp。memory_search返回带有文件路径和行号的片段(单片段最大 700 字符),memory_get按路径和行范围精确读取。 - 心跳系统(Heartbeat) 实现了 Agent 的主动行为能力。默认每 30 分钟在主会话中触发一次 Agent 回合,提示词指示 Agent 读取 HEARTBEAT.md 并严格执行其中的任务。如果没有需要关注的事项,Agent 回复
HEARTBEAT_OK,OpenClaw 会抑制这条消息的外发投递(用户永远看不到无意义的心跳确认)。如果有重要事项(重要邮件、即将到来的日历事件、超过 8 小时无互动),Agent 则发送实际的提醒消息。心跳与 Cron 形成互补:心跳适合批量检查、需要对话上下文、时间可以漂移的场景;Cron 适合精确定时、任务隔离、一次性提醒的场景。
与 Claude Code、Cursor、AutoGPT 的架构差异
- 将 OpenClaw 的提示词架构放在 AI Agent 生态中对比,能更清晰地看到其独特定位和设计取舍。
- Claude Code 使用 110+ 个独立 prompt 字符串条件组装,核心通过
CLAUDE.md单文件提供项目上下文,但没有跨会话持久记忆——每次启动都是全新状态。它的子 Agent 系统(Explore、Plan、Task)针对编码场景高度特化。相比之下,OpenClaw 的多文件 prompt 系统(SOUL.md + AGENTS.md + USER.md + IDENTITY.md + TOOLS.md + HEARTBEAT.md)在表达力上远超单个 CLAUDE.md,且通过 MEMORY.md + 每日日志实现了真正的持久记忆。两者的根本差异在于:Claude Code 是有状态会话内、无状态会话间的编码工具,OpenClaw 是始终在线、跨会话持久化的个人助手。 - Cursor 采用完全静态的系统提示词(不含任何用户/代码库个性化文本),通过
.cursor/rules/目录提供可按需获取的规则菜单——模型通过fetch_rules()工具调用来加载规则,而非预注入。这种设计最大化了 prompt 缓存效率,但牺牲了人格化能力。OpenClaw 走了相反的路线:每次运行动态组装、注入完整人格和上下文,通过仅包含时区(不含动态时间) 这一巧妙设计来兼顾缓存命中率。 - AutoGPT 使用单体结构化 prompt(包含目标、命令列表、资源、评估标准),要求模型以固定 JSON 格式(thoughts + command)响应,形成”构建 prompt → LLM → 解析执行 → 存储结果 → 循环”的闭环。其记忆依赖向量数据库(Pinecone/ChromaDB),与 OpenClaw 的”Markdown 文件为真相来源、数据库为派生索引”形成鲜明对比。AutoGPT 是目标驱动的——给定目标后自主循环到完成;OpenClaw 是消息驱动的——响应来自消息平台的事件并保持长期在线。
- LangChain/LangGraph 提供了最灵活的程序化 prompt 模板系统(
ChatPromptTemplate支持变量插值、Jinja 2 模板),通过图节点编排多 Agent 工作流,但抽象层次较高,prompt 管理分散在多个 Python 文件中。OpenClaw 的哲学正好相反:一个 Markdown 文件就是一个关注点,人类可以直接阅读和编辑,无需理解任何编程抽象。 - 核心差异:OpenClaw 将提示词工程从代码领域拉回到了文档领域(对于 AI 而言,文档亟代码)。 其他框架的提示词是代码的一部分(字符串常量、模板函数、条件组装逻辑),而 OpenClaw 的 prompt 就是工作区里的文件——可以
git diff、可以grep、可以直接用编辑器修改、可以被 Agent 自己更新。这使得”调试 Agent 行为”等价于”阅读 Markdown 文件”,对于非程序员用户和快速迭代场景是巨大优势。代价则是缺少 IDE 集成、设置复杂度较高、以及内存安全需要额外注意(明文凭证存储在文件系统中)。
文件驱动架构的启示
- OpenClaw 的提示词系统架构验证了一个反直觉的观点:最强大的智能体配置系统可能不需要任何数据库或编程框架,只需要结构良好的纯文本文件。 这种设计带来了三个核心启示。
- 第一,关注点分离在提示词工程中同样重要——将人格(SOUL. Md)、身份(IDENTITY. Md)、用户画像(USER. Md)、操作手册(AGENTS. Md)、环境配置(TOOLS. Md)拆分为独立文件,使得每个维度可以独立迭代,远优于单一巨型 prompt 文件。
- 第二,“元数据进提示词、内容按需加载” 的模式(技能系统的 JIT 加载、记忆系统的 search-then-get)是管理大规模工具和知识库时控制 token 成本的最佳实践。
- 第三,Agent 的自我修改能力(更新 SOUL. Md、维护 MEMORY. Md、清理 HEARTBEAT. Md)创造了一种独特的”文件即认知”范式——当 Agent 的所有”思维”都是人类可读的文本文件时,信任和透明度问题得到了根本简化。对于正在构建 AI Agent 的开发者而言,OpenClaw 展示的不仅是一个特定实现,更是一种值得深入思考的架构哲学。
Hermes 架构
- Hermes 的核心是对话循环。骨架清晰:Agent 接收用户消息,带上工具参数调用大模型,如果返回工具调用就逐个执行,把结果追加到上下文,然后继续调用模型,循环直到给出最终回复。
- 两个关键细节:
- 有迭代预算限制,默认最多 90 轮,防止 Agent 陷入死循环
- 循环结束后触发后台 review 流程,这是整个系统最核心的设计,也是 Skill 和记忆自动沉淀的入口
智能体自主精选记忆 + 定时提醒机制
- 在会话运行的固定间隔里,智能体会收到一条内部系统提示,让它回头复盘:刚才发生的事儿里,有没有值得存下来的?整个过程不需要用户插手,智能体自己扫一遍近期操作,觉得对未来有用,就写进记忆文件。
- 结果就是:记忆库始终是精选内容,而不是乱七八糟的聊天垃圾堆。
Harness:六层核心组件
- 一个成熟的 Harness 大致可以拆成六层:
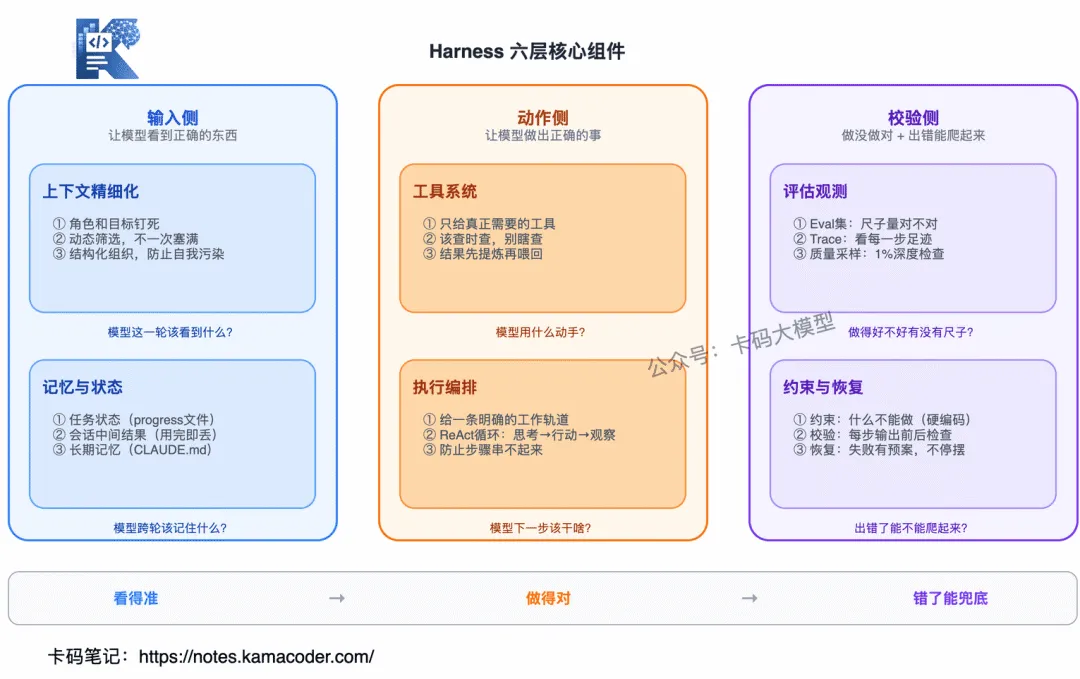
- 输入侧(让模型看到正确的东西):上下文精细化管理 + 记忆与状态管理
- 动作侧(让模型做出正确的事):工具系统 + 任务执行编排
- 校验侧(让模型知道做没做对 + 出错能爬起来):评估观测 + 约束恢复
RAG 系统:知识检索增强生成
RAG 的基础知识
- 什么是 RAG?
- 检索增强生成(Retrieval-Augmented Generation,RAG)是一种结合了信息检索和文本生成的技术。它的核心思想是:在生成回答之前,先从外部知识库中检索相关信息,然后将检索到的信息作为上下文提供给大语言模型,从而生成更准确、更可靠的回答。
- 因此,检索增强生成可以拆分为三个词汇。检索是指从知识库中查询相关内容;增强是将检索结果融入提示词,辅助模型生成;生成则输出兼具准确性与透明度的答案。
- RAG 的基本工作流程
- 一个完整的 RAG 应用流程主要分为两大核心环节。在数据准备阶段,系统通过数据提取、文本分割和向量化,将外部知识构建成一个可检索的数据库。随后在应用阶段,系统会响应用户的提问,从数据库中检索相关信息,将其注入 Prompt,并最终驱动大语言模型生成答案。
场景题
-
设计一个订餐系统,如何设计状态流转?
- 如果让我设计订餐系统的状态流转,我会先把它拆成几个核心对象:订单、支付、配送、售后,然后围绕订单主状态去设计状态机。订单一般会经历:待支付 → 已支付 → 商家接单 → 备餐中 → 配送中 / 待自取 → 已完成,同时还要考虑异常分支,比如 已取消、退款中、已退款、接单失败 等。设计上我会强调一点:状态流转一定要单向、可追踪、幂等,不能随便跳状态,比如“待支付”可以变“已取消”或“已支付”,但不能直接跳到“配送中”。这样做的目的是保证状态清晰,方便后续处理库存扣减、优惠券核销、骑手调度、退款补偿这些业务动作。
- 订餐系统本质上是一个事件驱动的状态机。比如用户下单后生成订单,支付成功事件驱动订单从“待支付”变成“已支付”;商家接单事件再推动进入“备餐中”;骑手取餐后变成“配送中”;用户确认收餐或超时自动确认后进入“已完成”。异常场景也要提前定义清楚,比如用户支付超时自动取消、商家拒单触发退款、配送失败进入售后状态。实现上通常会用状态字段 + 状态流转表 + 操作日志来控制,更新时做状态校验,保证只有合法流转才能成功;同时结合消息队列处理异步事件,结合定时任务处理超时取消、自动确认这类流程。订餐系统的状态设计核心不是状态有多少,而是状态边界是否清晰、流转是否合法、异常补偿是否完整。
-
如果大模型接口有超时或抖动,怎么保证正确性和一致性?哪些场景可以重试,哪些场景禁止重试?
- 如果大模型接口存在超时或抖动,把问题分成两层看:调用层的可靠性和业务层的一致性。调用层要做超时控制、熔断、限流、隔离、降级,避免单点接口抖动把整个系统拖垮;业务层更关键,核心是做到请求幂等、结果可追踪、状态可回放。比如每次请求都带唯一
requestId,先落请求日志和业务状态,再发起模型调用;返回结果后做状态更新,确保同一个请求即使因为超时看起来“失败了”,后面补偿查询或重复到达时也能识别这是同一笔请求,而不是重复执行。对于强一致要求的场景,不能把“大模型返回成功”直接等同于“业务成功”,而是要通过状态机把流程拆成待处理、处理中、已完成、已失败几种状态,必要时配合消息队列、任务表和补偿机制保证最终一致性。面试里我会强调一句:大模型调用本身通常很难做到强一致,只能通过幂等、状态机和补偿机制保证业务一致性。 - 是否允许重试,关键看这个调用是不是幂等,以及是否会引发重复副作用。像纯查询类、纯生成类、未落业务结果的内部推理类,一般都可以重试,比如“帮我总结一段文本”“做一次分类判断”“提取关键词”,因为即使重试,最多是多花一点算力,不会破坏业务状态;但也要注意,大模型结果可能有随机性,所以如果业务要求结果稳定,最好固定模型版本、温度参数,必要时缓存首次结果。相反,像已经触发外部副作用的场景通常禁止直接重试,比如已经根据模型结果发了短信、发了优惠券、扣了库存、创建了工单、调用了支付或审批流,这种如果简单重试,容易造成重复发放、重复扣减、重复提交。对于这类场景,正确做法不是“失败就重试整个流程”,而是把流程拆开:模型推理和业务落库分阶段处理,先做幂等校验,再决定是否补偿。总结成面试话术就是:可重试的是无副作用或天然幂等的调用;禁止直接重试的是会造成资金、库存、通知、工单、审批等外部副作用的调用,这类场景必须靠幂等键、状态机和补偿机制来保证一致性。
- 如果大模型接口存在超时或抖动,把问题分成两层看:调用层的可靠性和业务层的一致性。调用层要做超时控制、熔断、限流、隔离、降级,避免单点接口抖动把整个系统拖垮;业务层更关键,核心是做到请求幂等、结果可追踪、状态可回放。比如每次请求都带唯一
知识复习汇总2
http://example.com/2025/02/21/Interview_2/