Linux 系统编程
Linux 系统编程
通用 Makefile 文件
- 通用 Makefile 文件的代码如下:
1 | |
目录相关操作
获取当前工作目录
- 我们可以调用库函数
getcwd()获取当前工作目录的绝对路径:

- 如果传入的
buf为NULL,且size为0,则getcwd()会调用malloc申请合适大小的内存空间,填入当前工作目录的绝对路径,然后返回malloc申请的空间的地址。- 注意:
getcwd()不负责free申请的空间,free是调用者的职责。
- 注意:
- 代码:
1 | |
- 也可以与库函数
error()来联动进行错误处理,从下图中的数据手册可以看到getcwd()出错的时候会设置errno这个参数:

- 库函数
error()的用法:
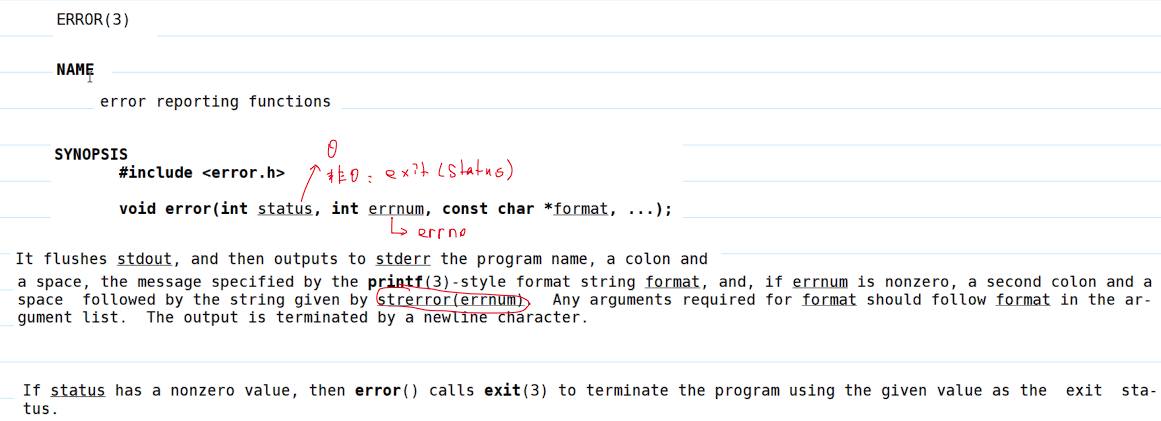
- 代码如下:
1 | |
- 运行结果:

改变当前工作目录
- 我们可以调用库函数
chdir()改变当前工作目录的绝对路径:

- 代码:
1 | |
- 注意:当前工作目录是进程的属性,也就是说每一个进程都有自己的当前工作目录。且父进程创建 (
fork)子进程的时候,子进程会继承父进程的当前工作目录。 - 运行结果:
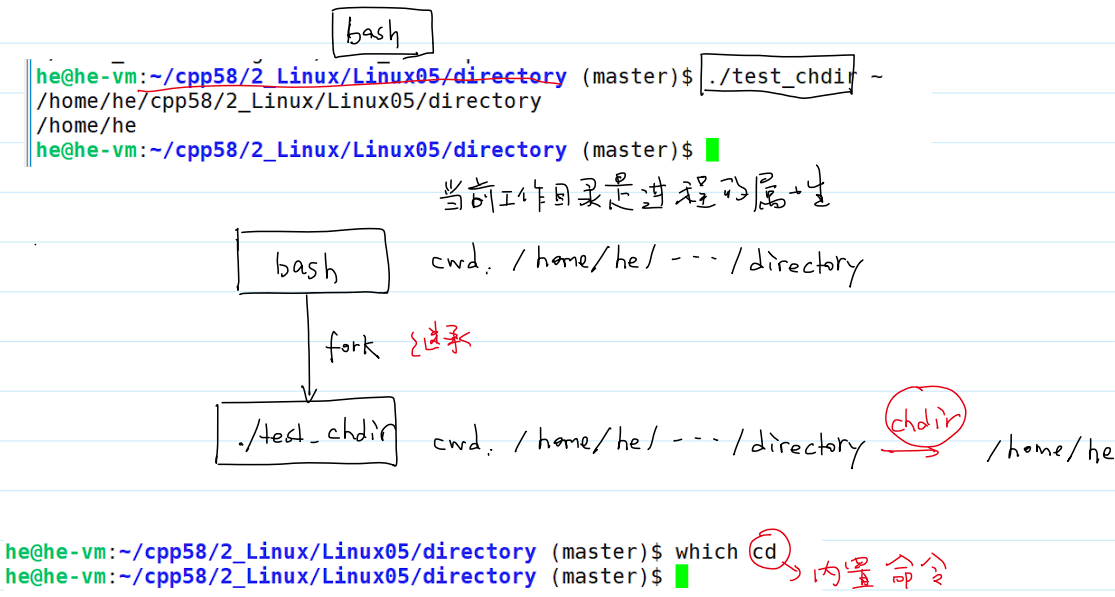
创建目录
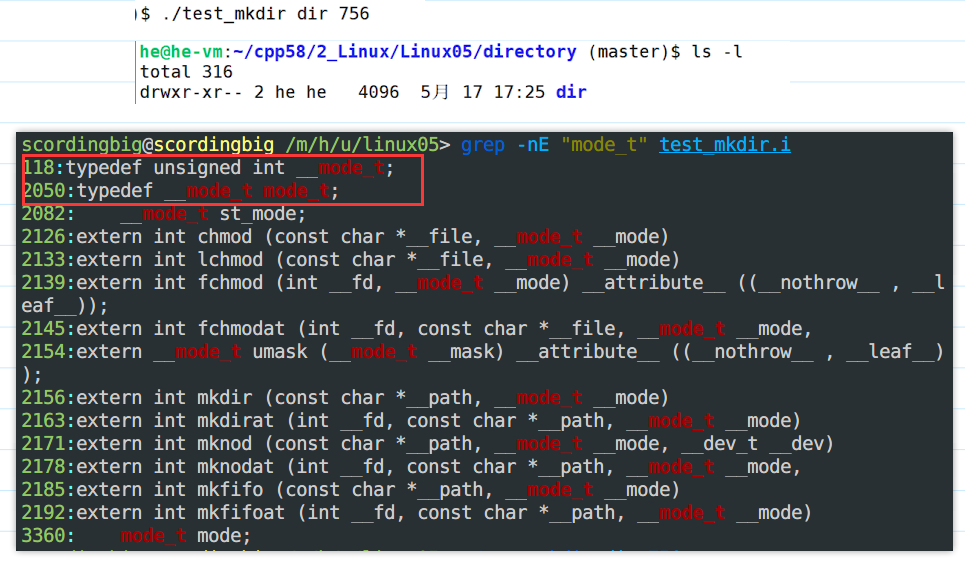
mkdir()函数可以用来创建目录。

- 代码:
1 | |
- 当不知道
mode_t的类型是什么的时候,可以使用以下方法来查看:
1 | |
- 运行结果:
删除空目录
rmdir()可以删除空目录。

- 代码:
1 | |
目录流
- 使用目录流,可以查看目录中的内容。
- 流模型:“流"类似"水流”,顺序访问流中的数据时,是不需要关注位置的。
- 目录流与文件流相比,文件流中的基本单位是字符或字节。而目录流中的基本单位是目录项。如下图所示:
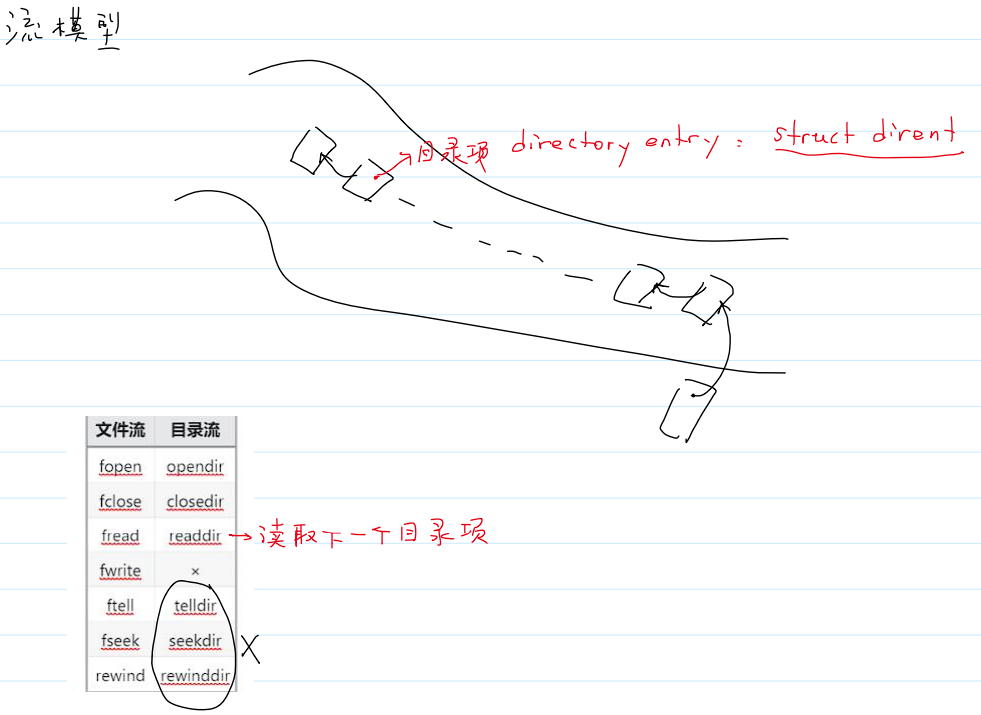
打开目录流
opendir()可以打开一个目录,得到一个指向目录流的指针DIR*。

关闭目录流
closedir()关闭目录流。

读取目录流
readdir()读目录流,得到指向下一个目录项的指针。
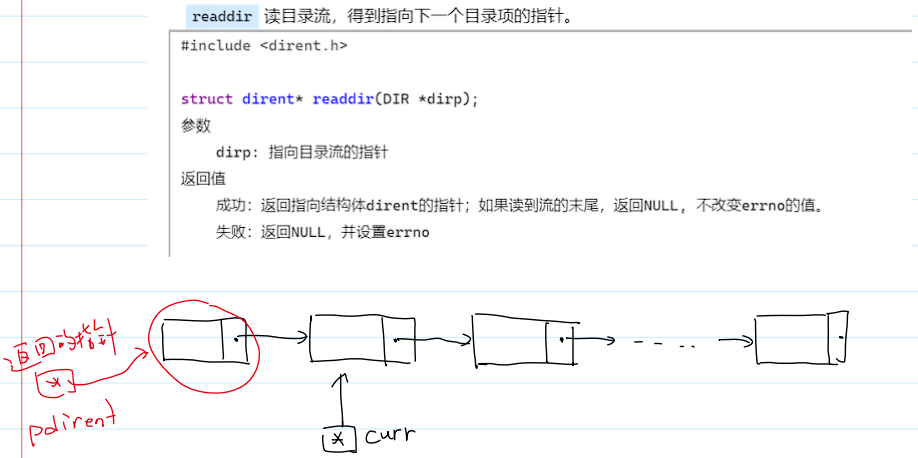
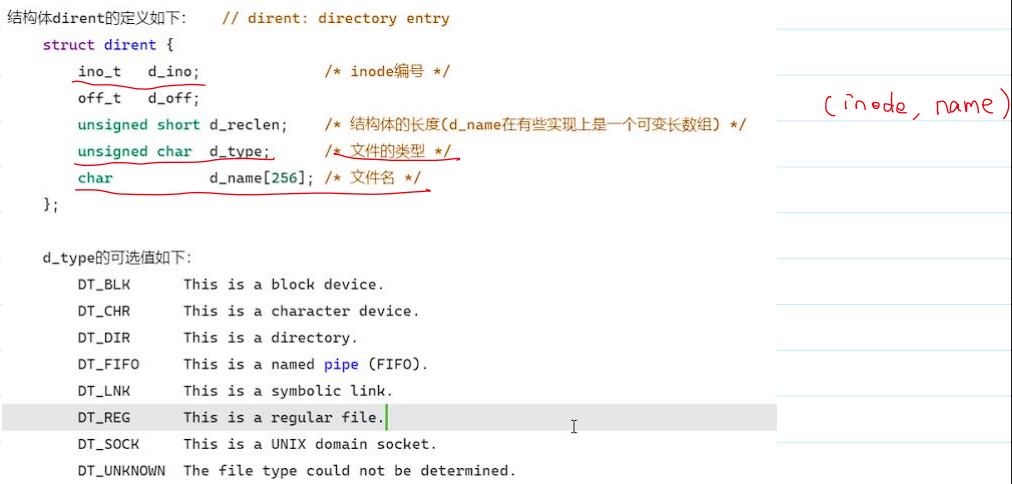
- 结构体
dirent的定义:
- 读取一个目录内的内容并打印的代码:
1 | |
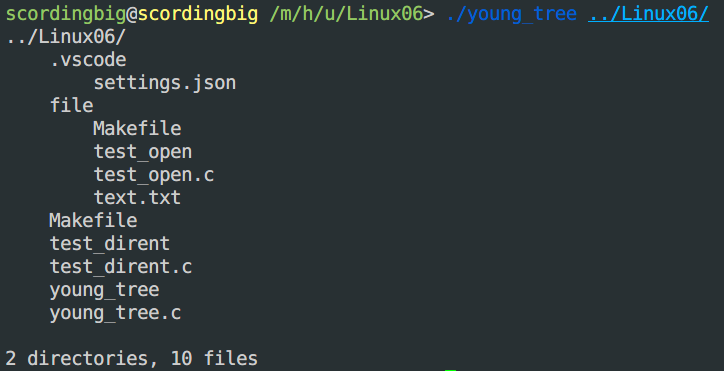
递归地打印目录
- 实现青春版
tree命令:输出内容分为三部分- 1)目录的名字;
- 2)递归打印每一个目录项;
- 3)最后是统计信息。
- 代码:
1 | |
- 效果:
文件相关操作
打开文件
- 系统调用
open()打开文件。- 打开成功:返回新的文件描述符(最小可用的文件描述符);
- 打开失败:返回
-1,设置errno。
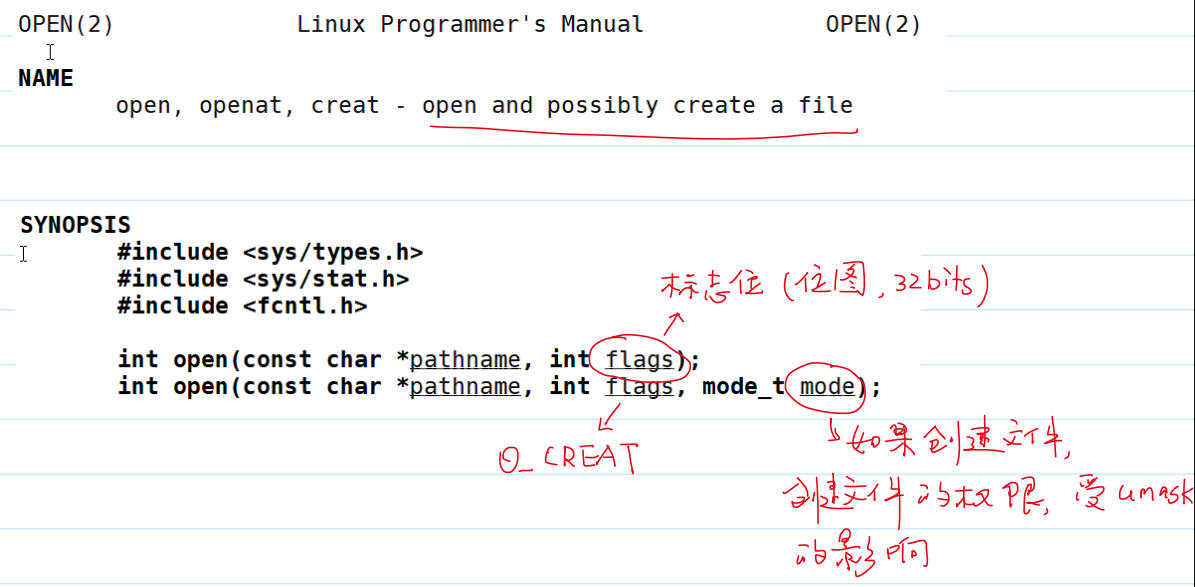
- 部分
flags的含义:
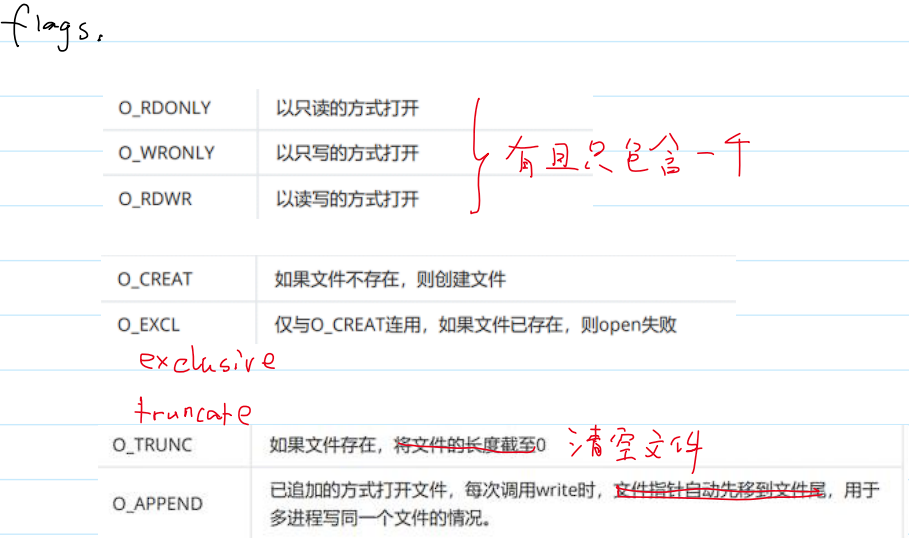
- 代码:
1 | |
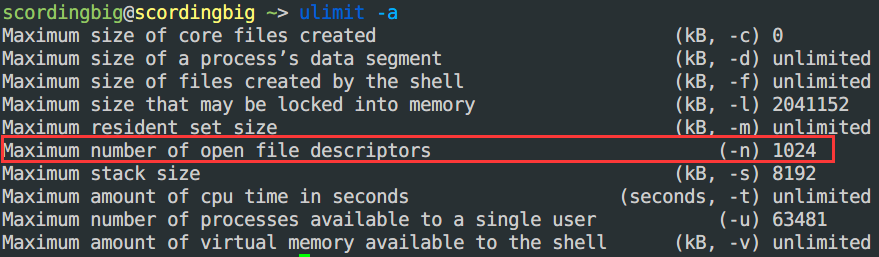
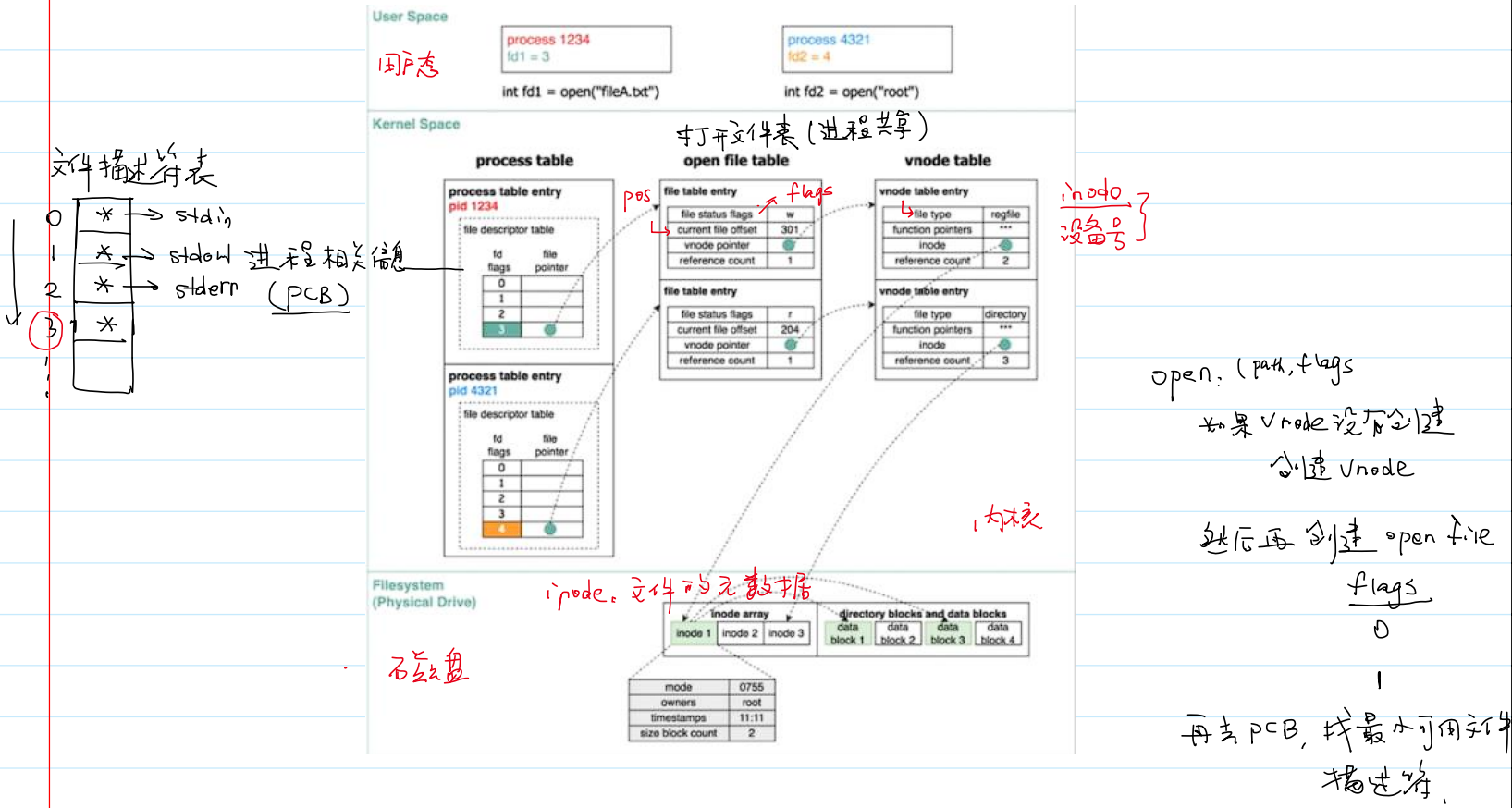
- 通过系统调用
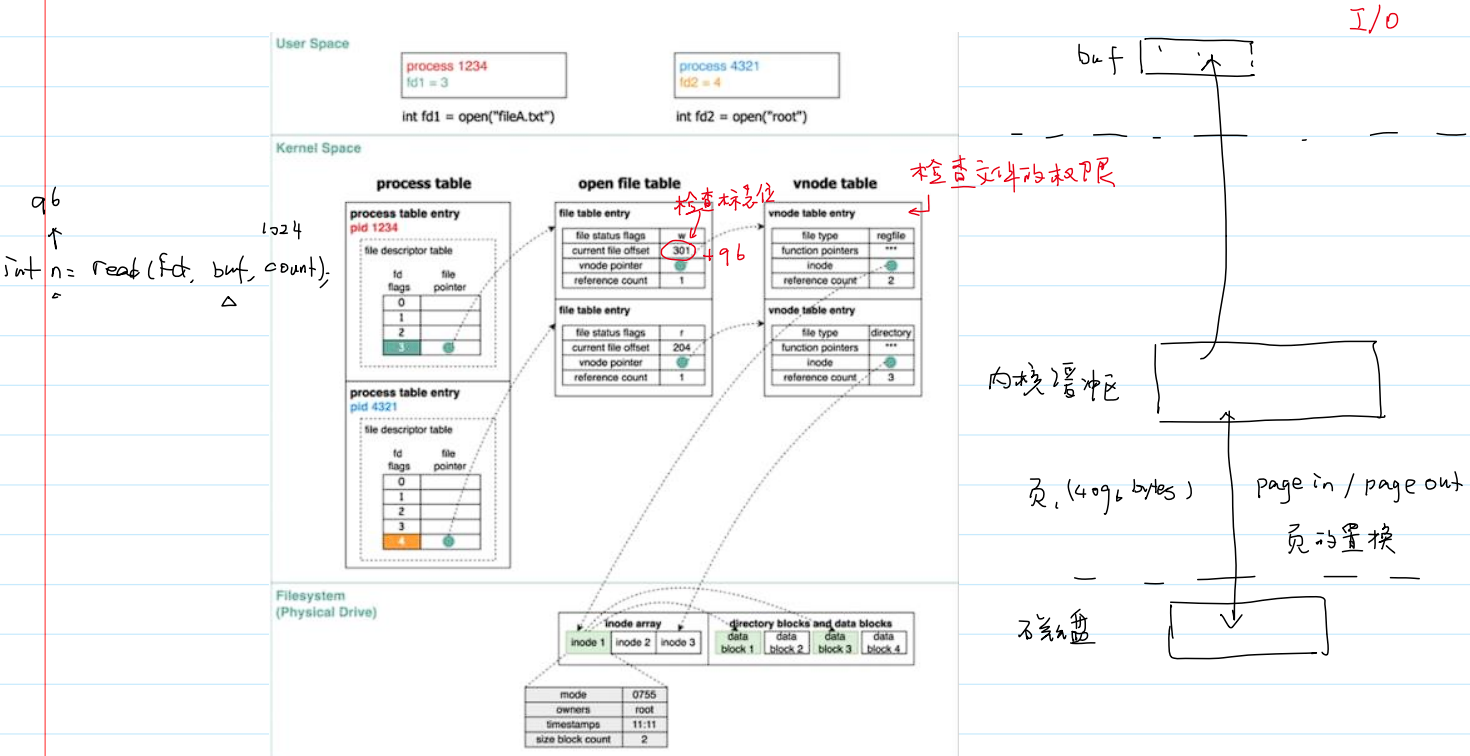
open()的过程介绍内核管理文件的数据结构:- 文件描述符表的数组长度默认是 1024,并且可以进行设置:
- 系统调用
open()的内核管理文件流程:
关闭文件
- 系统调用
close()关闭文件。- 关闭成功:返回
0; - 关闭失败:返回
-1,设置errno。
- 关闭成功:返回
- 系统调用
close()的内核管理文件流程:
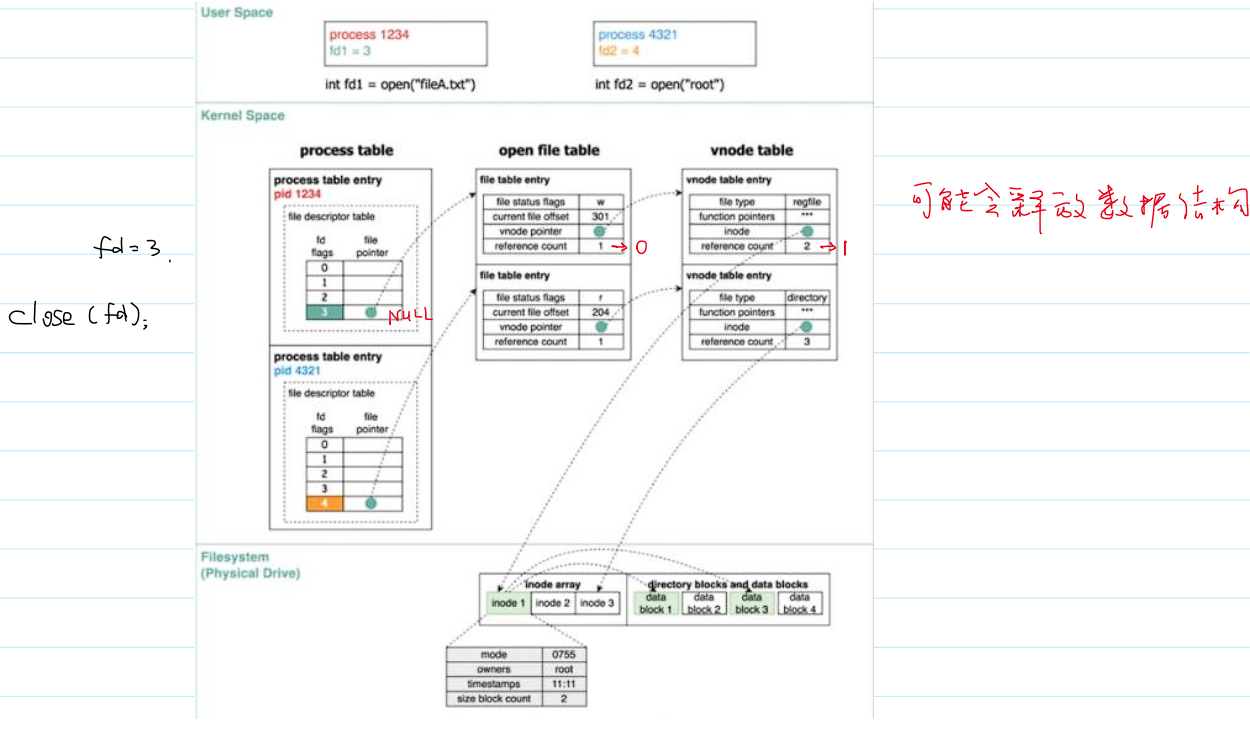
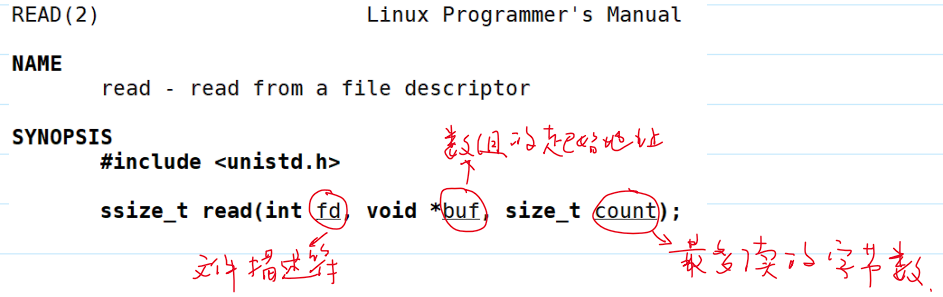
读取文件
- 系统调用
read()读取文件。- 读取成功:返回实际读取的字节数目(
0,表示读取的起始位置在文件末尾); - 读取失败:返回
-1,设置errno。
- 读取成功:返回实际读取的字节数目(
- 系统调用
read()的内核管理文件流程:
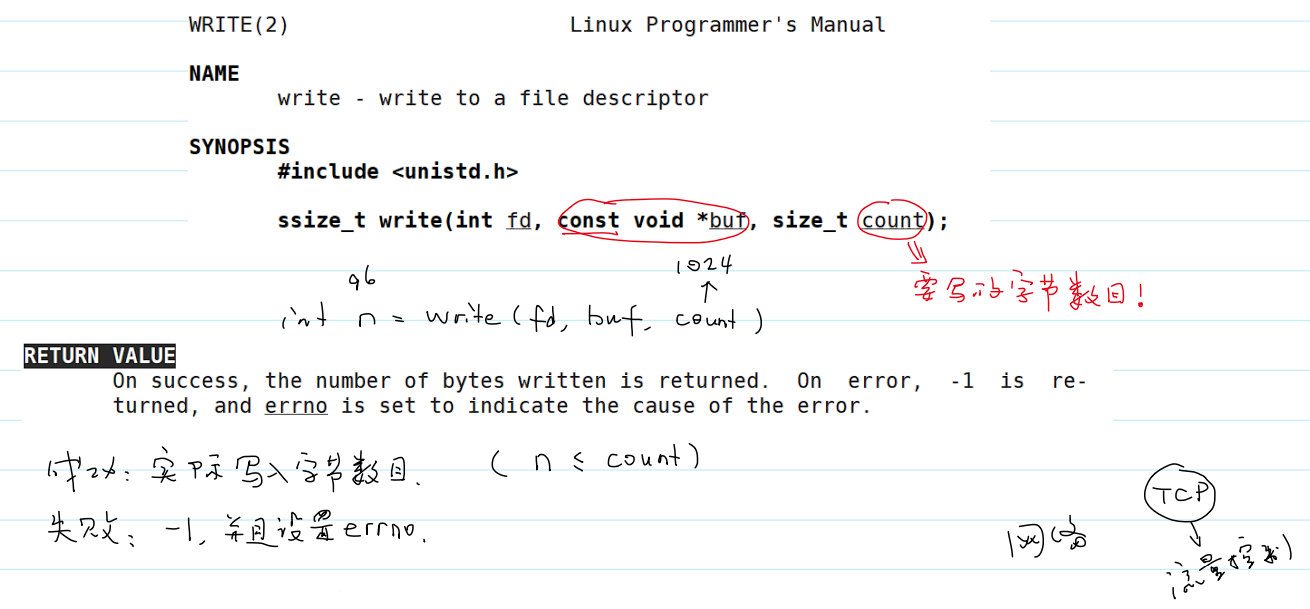
写入文件
- 系统调用
write()读取文件。- 写入成功:返回实际写入字节数目(其中
n≤count); - 写入失败:返回
-1,设置errno。
- 写入成功:返回实际写入字节数目(其中
- 系统调用
write()的内核管理文件流程:
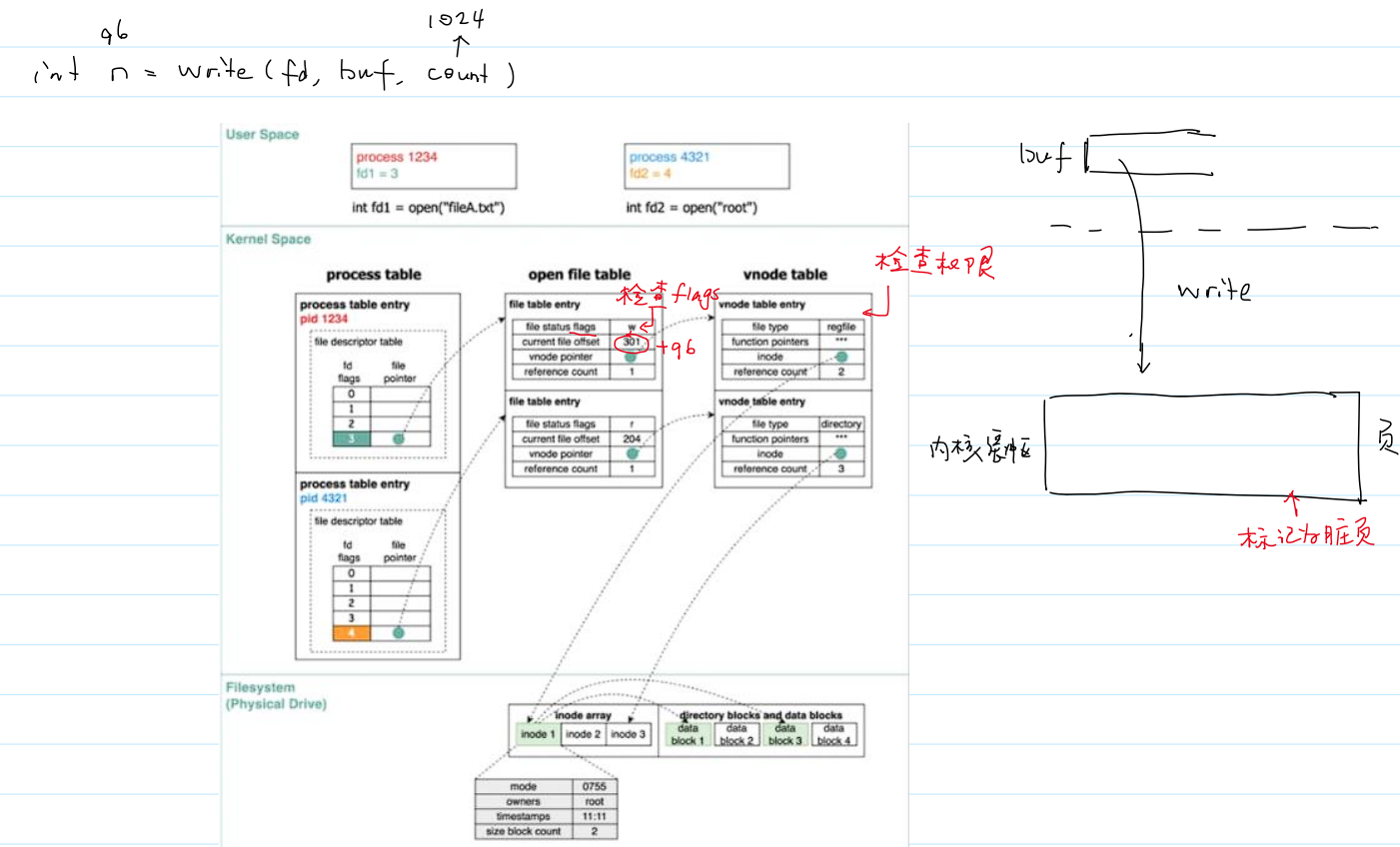
修改文件偏移量
- 系统调用
lseek()修改文件偏移量,本质上就是修改current file offset (pos)的数值。- 修改成功:返回文件的位置(距离文件开头的字节数目);
- 修改失败:返回
-1,设置errno。

- 系统调用
lseek()的内核管理文件流程:
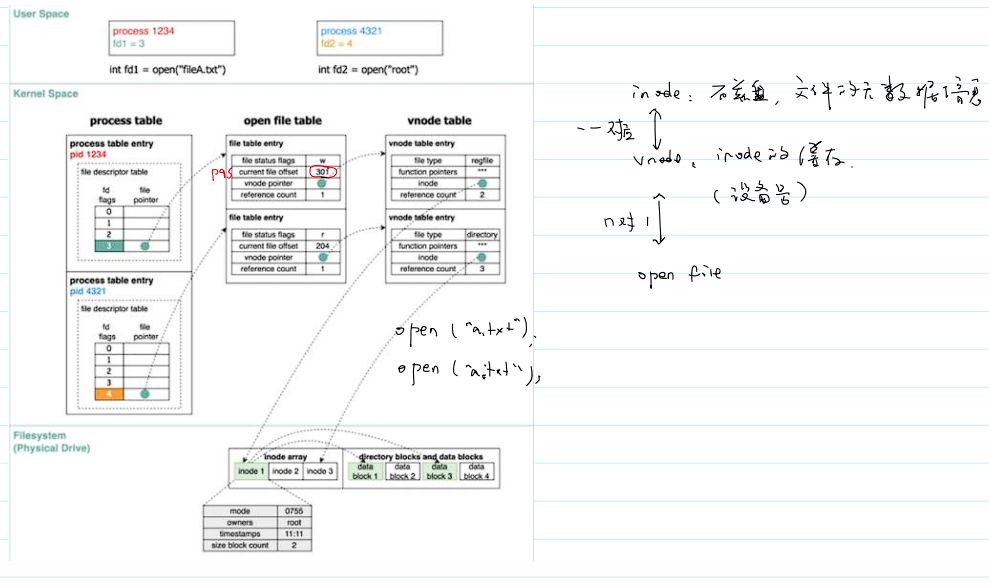
- 文件库函数和文件系统调用之间的关系:

文件描述符和文件流的异同
- 文件描述符的系统调用与文件流的函数:

- 文件描述符和文件流的数据访问流程:
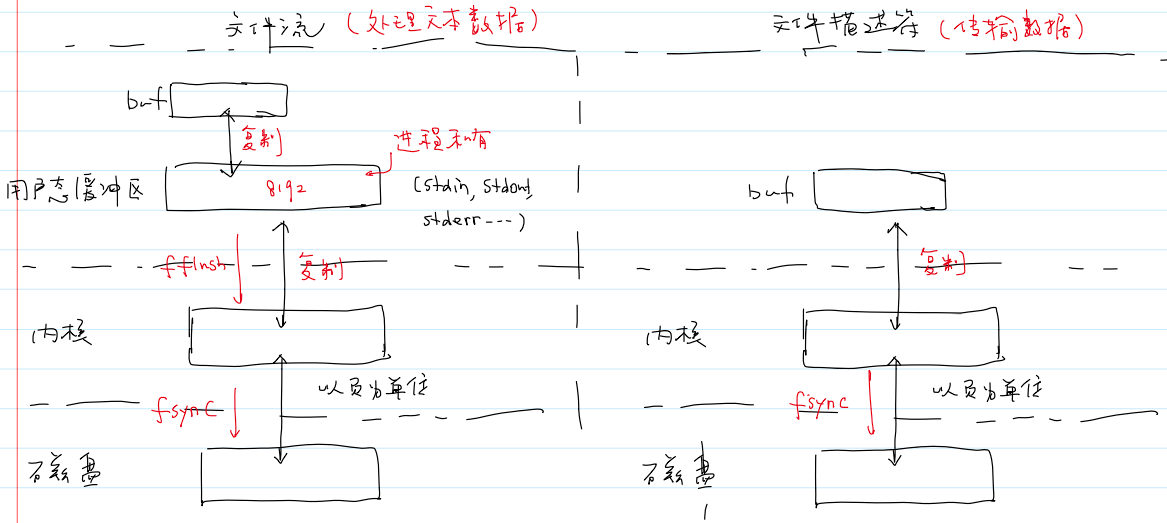
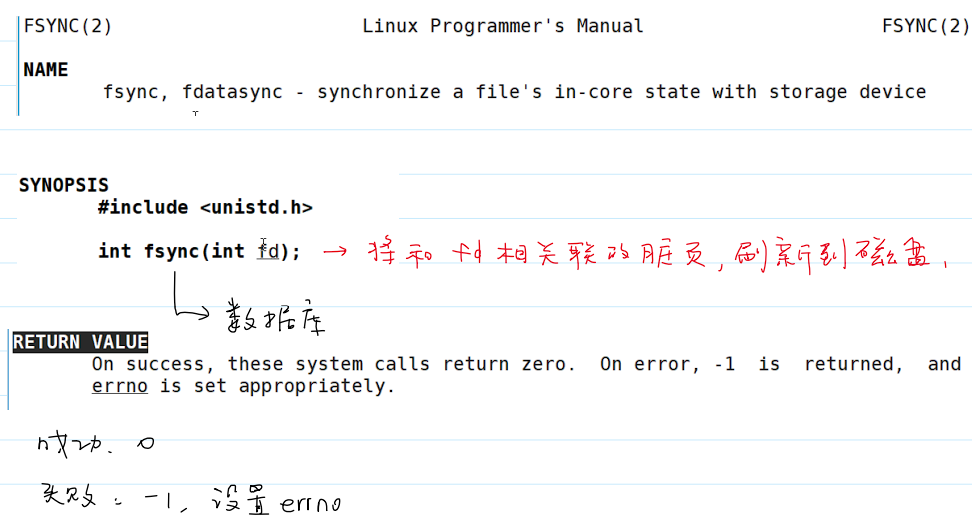
同步内存中所有已修改的文件数据到储存设备
- 函数
fsync()同步内存中所有已修改的文件数据到储存设备。- 将和文件描述符相关联的脏页刷新到磁盘。
- 刷新成功:返回
0; - 刷新失败:返回
-1并设置errno。
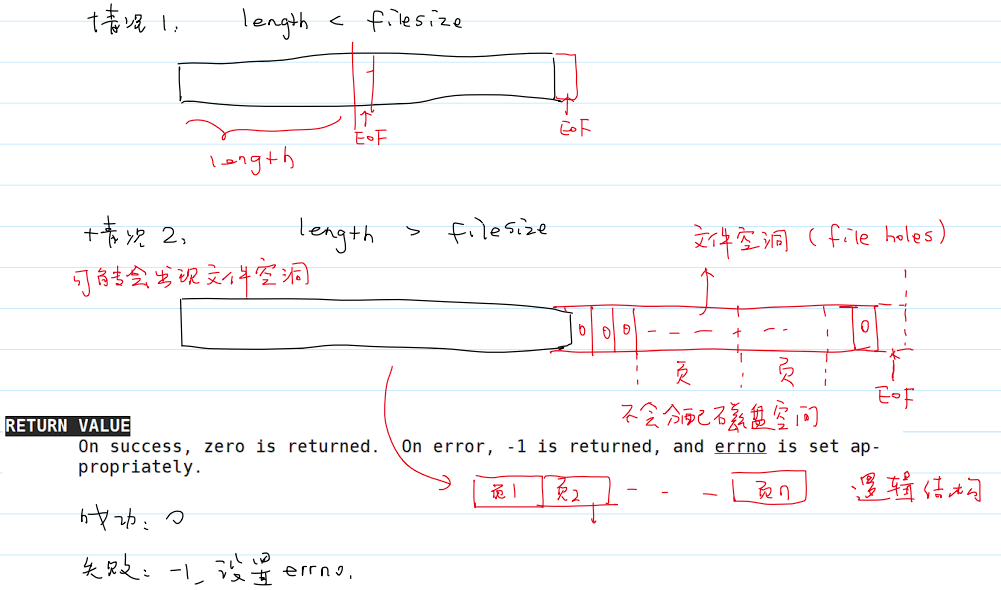
修改文件长度
- 函数
ftruncate()修改文件长度为length个字节大小。 - 用法如下:
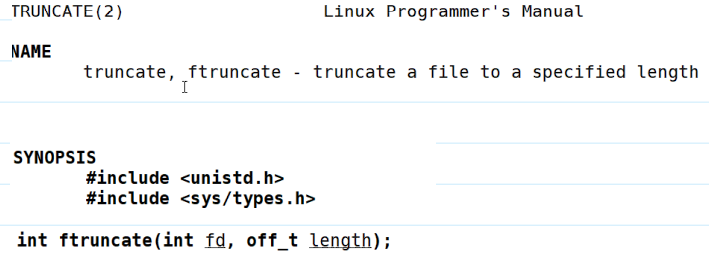
- 修改文件的长度有两种情况:
- 情况二可能会出现文件空洞的情况,此时数据全为
0的页不会分配磁盘空间。
- 情况二可能会出现文件空洞的情况,此时数据全为
- 使用代码示例:
1 | |
- 关于文件空洞的测试:
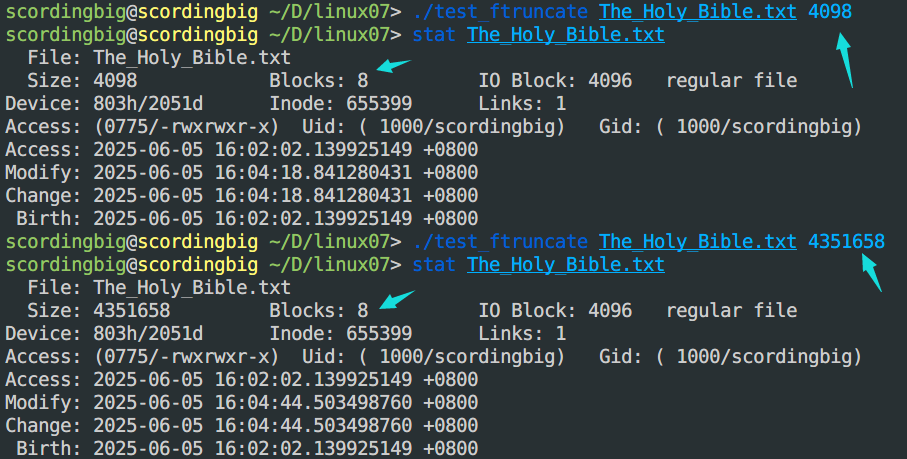
获取文件状态信息
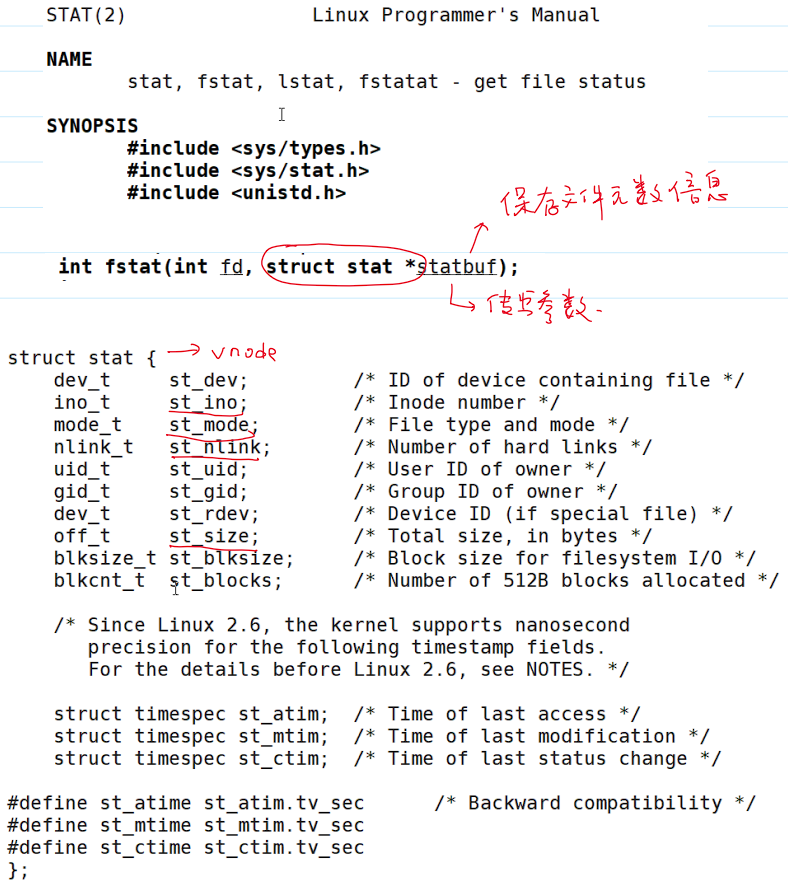
- 函数
fstat()用于获取文件状态信息。- 获取成功:返回
0; - 获取失败:返回
-1,设置errno。
- 获取成功:返回
- 其具体用法和状态信息结构体如下:
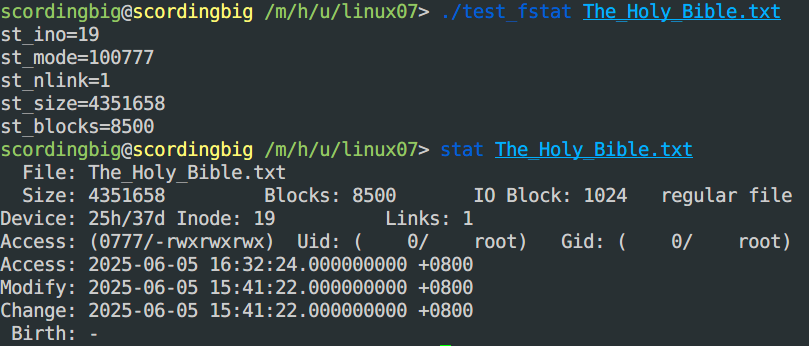
- 代码示例:
1 | |
- 打印结果:
文件描述符的复制
- 系统调用
dup()用于对文件描述符的复制。- 复制成功:返回新的文件描述符;
- 复制失败:返回
-1,设置errno。
- 其具体用法如下,分为
dup()和dup2()两个系统调用:

- 系统调用
dup()的内核管理文件流程:
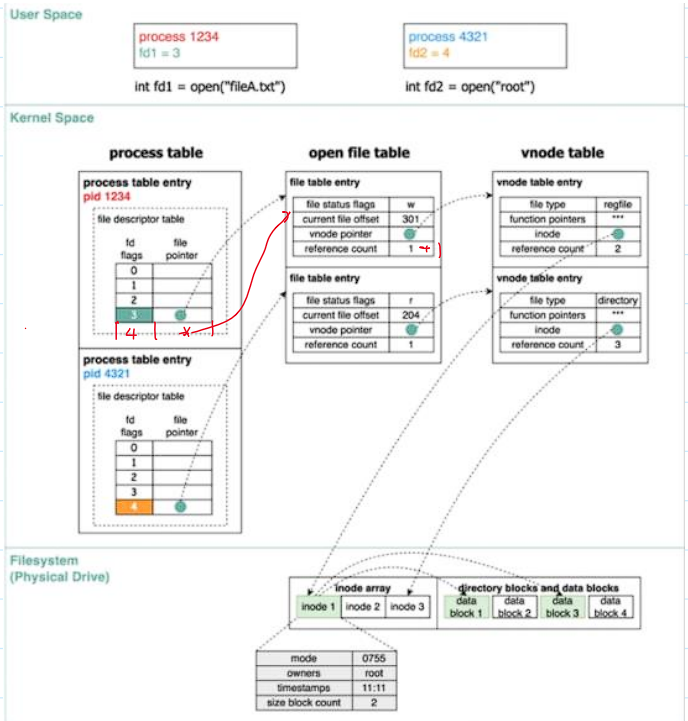
- 使用
dup()函数实现重定向:
1 | |
- 使用
dup2()函数实现重定向:
1 | |
- 分别执行完两个代码的运行结果:
- 第一个代码重定向
STDERR_FILENO文件描述符到application.log文件,写入一段语句; - 第二个代码同样重定向
STDERR_FILENO文件描述符到application.log文件,写入一段语句。
- 第一个代码重定向
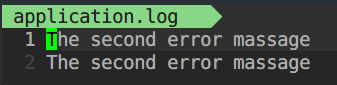
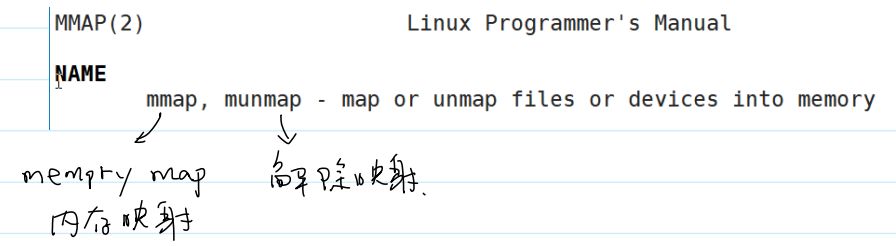
零拷贝(mmap)
- 系统调用零拷贝(
mmap())能够省去内核态和用户态的内存拷贝。
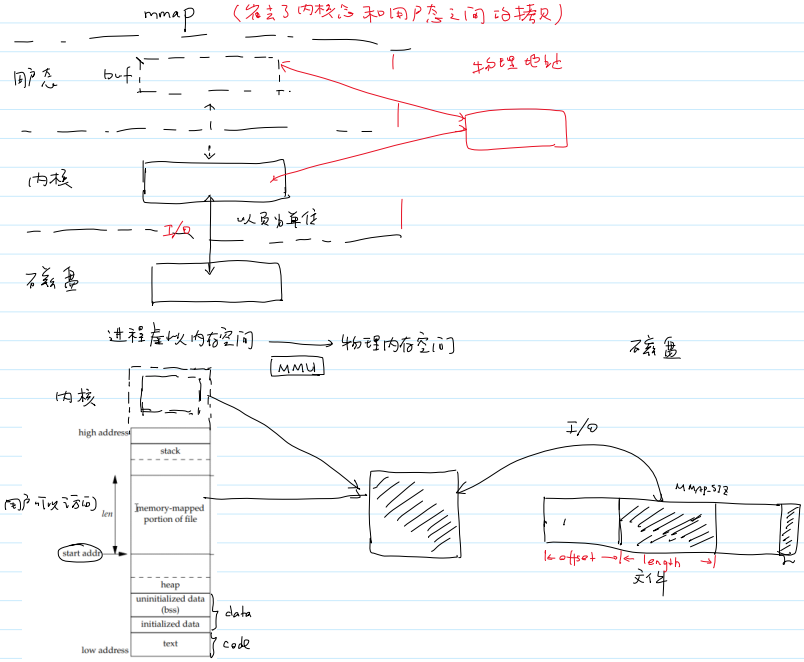
- 系统调用零拷贝(
mmap())的工作原理:- 相当于将文件的一部分内存通过
I/O操作拷贝到物理内存中,并且内核态和用户态共用这部分内存,不再需要重复拷贝。
- 相当于将文件的一部分内存通过
- 系统调用零拷贝(
mmap()和munmap())的使用方法:

- 系统调用零拷贝(
mmap()和munmap())的返回值:

- 系统调用零拷贝(
mmap()和munmap())的复制大文件使用场景:
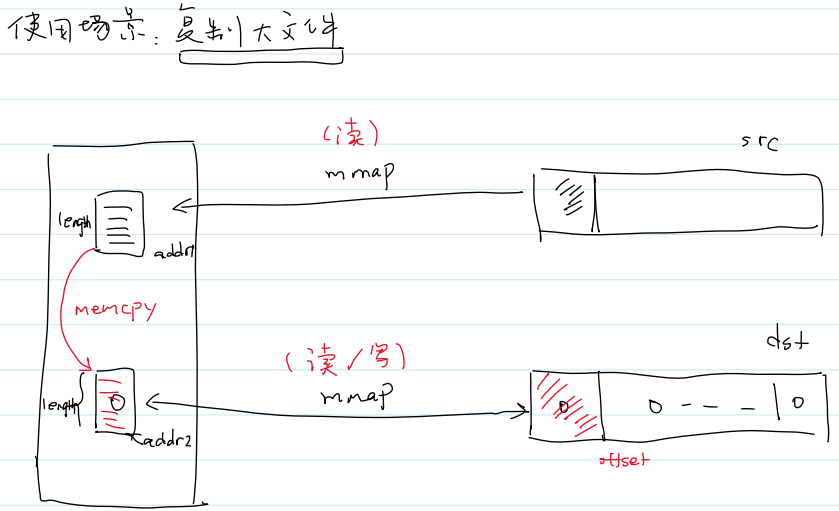
- 代码示例:
1 | |
CPU 的虚拟化
前置知识
- 内核的职责:管理硬件资源
- 共享资源的方式:
- 时分共享(CPU)
- 空分共享(内存)
- 操作系统通过让一个进程运行一段时间,然后切换到其它进程,缺点是会造成性能损失(需要进行上下文切换)。
- 如何实现 CPU 的时分共享?
- 底层机制:如何进行上下文切换
- 上层策略:调度策略
认识进程
- 用户角度:进程就是正在执行的程序
- 内核角度:要执行的任务(
struct task_t)- 进程之间必须隔离,进程之间是相互看不到的,感知不到另外的进程存在。
- 以进程的角度看,就像它独占计算机的所有资源(抽象机制:CPU 的虚拟化)。
xv6操作系统的进程相关结构体:

底层机制:实现上下文切换的三种方式及优缺点
- 指标:
- 性能:不应该增加太多的系统开销
- 控制权:操作系统应该保留控制权
方式一:直接运行(无限制)
- 优点:简单、快
- 缺点:没有控制权、不安全。
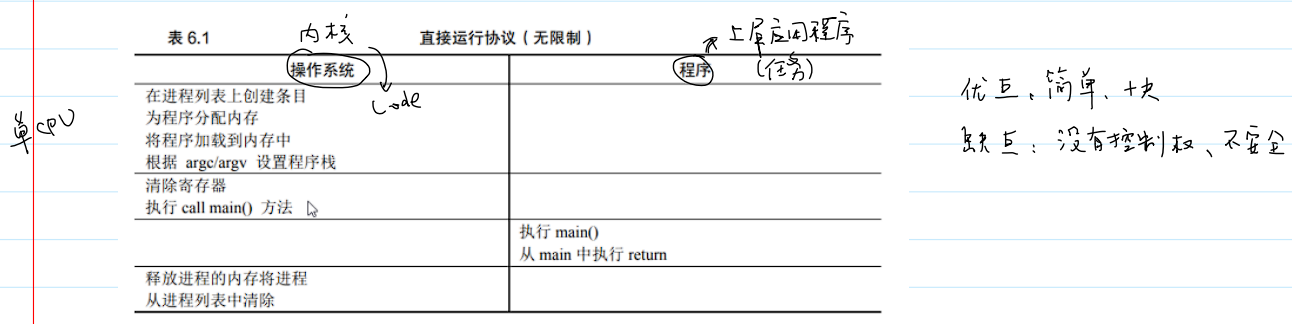
- 如何限制应用程序的权限?
- 不能让用户态应用程序访问非法的内存空间和执行一些特权指令。
- 需要硬件的协助即 CPU 的模态(模式):
- 用户态:应用程序(不能访问非法的内存空间和执行一些特权指令)
- 内核态:操作系统(可以访问机器的所有资源)
方式二:受限直接运行协议
- 应用程序如何执行特权操作?
- 通过系统调用!

- 通过特殊指令
trap来切换用户态和内核态:- 缺点在于控制权不是主动掌握在操作系统上。
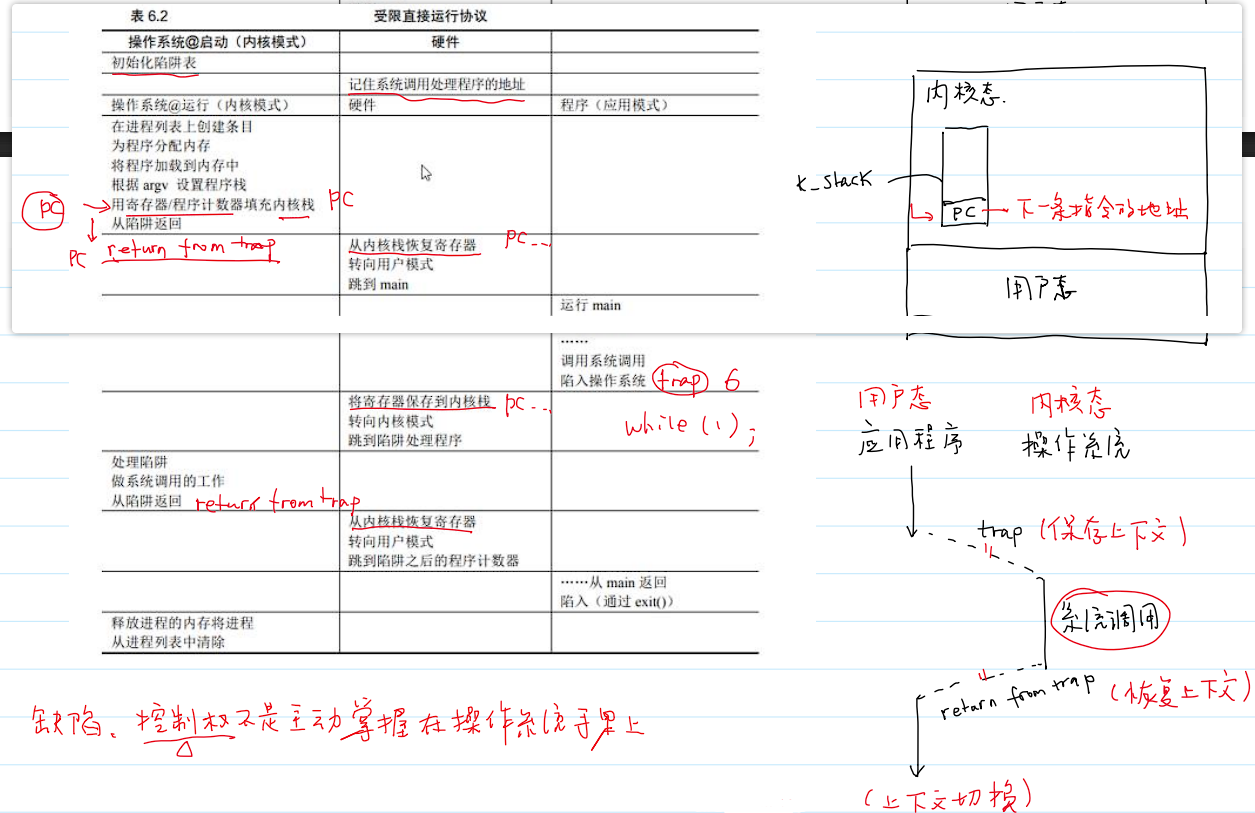
方式三:受限直接运行协议(时钟中断)
- 方式二采用协作(
yield())的方式,等待系统调用。 - 方式三采用非协作方式(抢占方式),操作系统能够主动进行控制。
- 时钟中断的方式:

- 受限直接运行协议(时钟中断):

- 进程之间是隔离的(感知不到内核和其他进程的存在)。
- 进程是资源分配的最小单位(任务<-分配资源)。
- 上下文切换:
- 调用系统调用
- 切换进程
和进程相关的常用命令
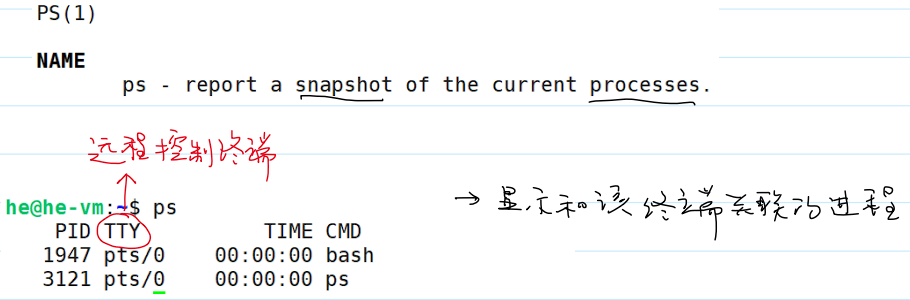
显示进程
ps命令显示和终端关联的进程:
ps x显示和用户关联的进程:
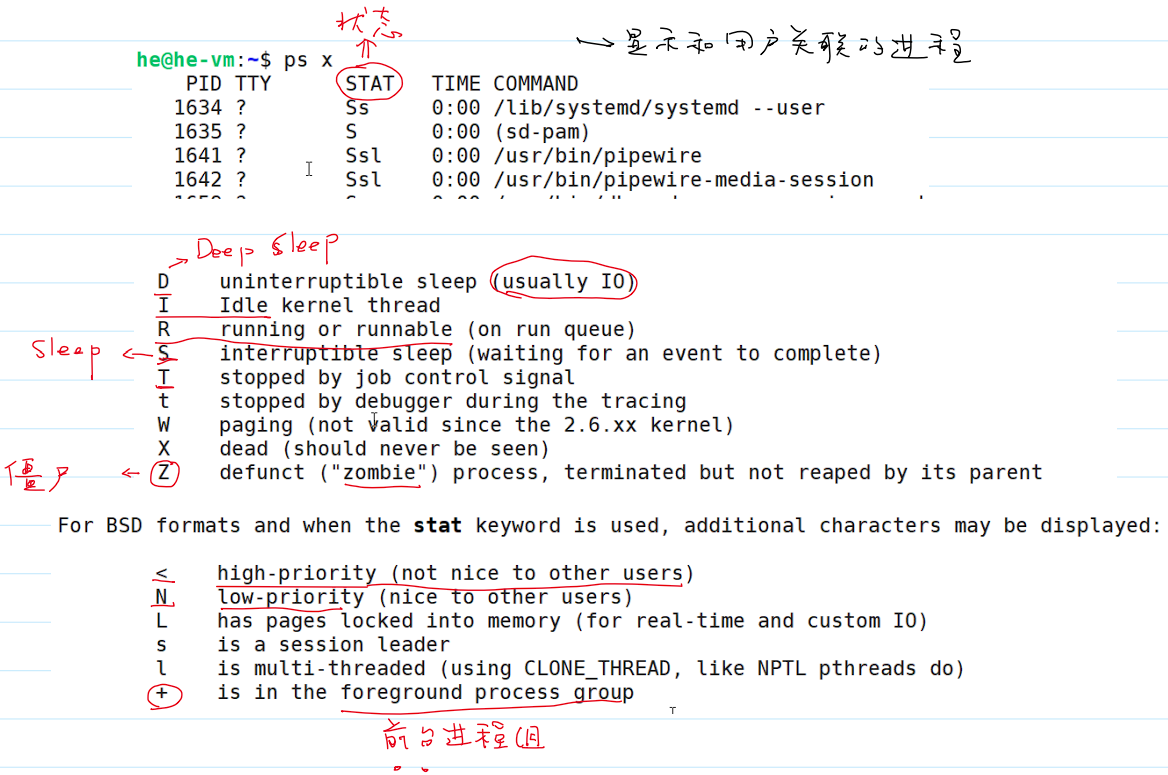
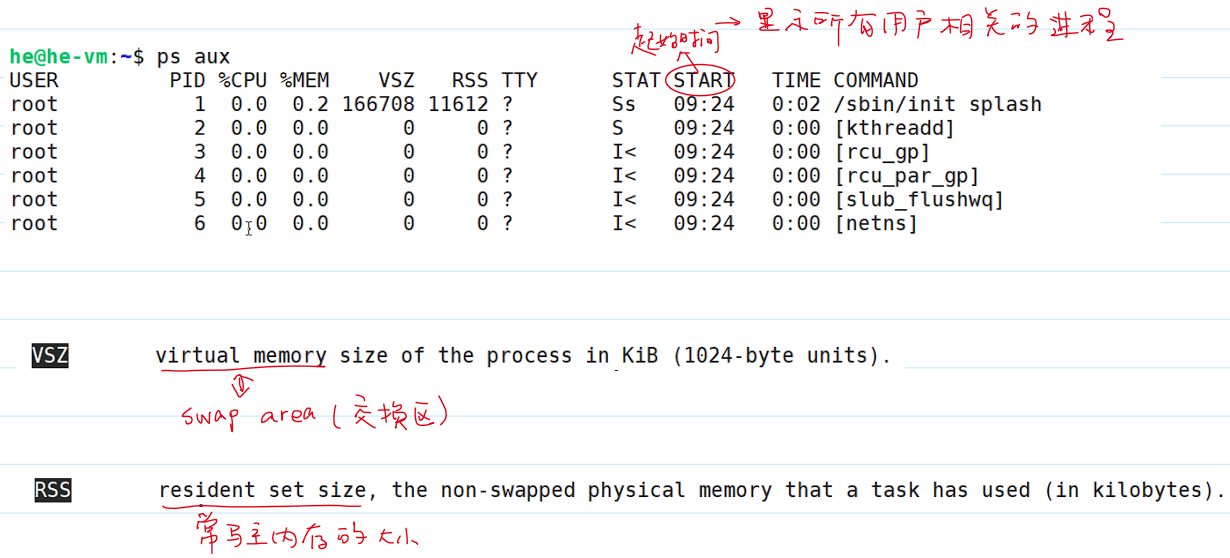
ps aux显示所有用户相关的进程:
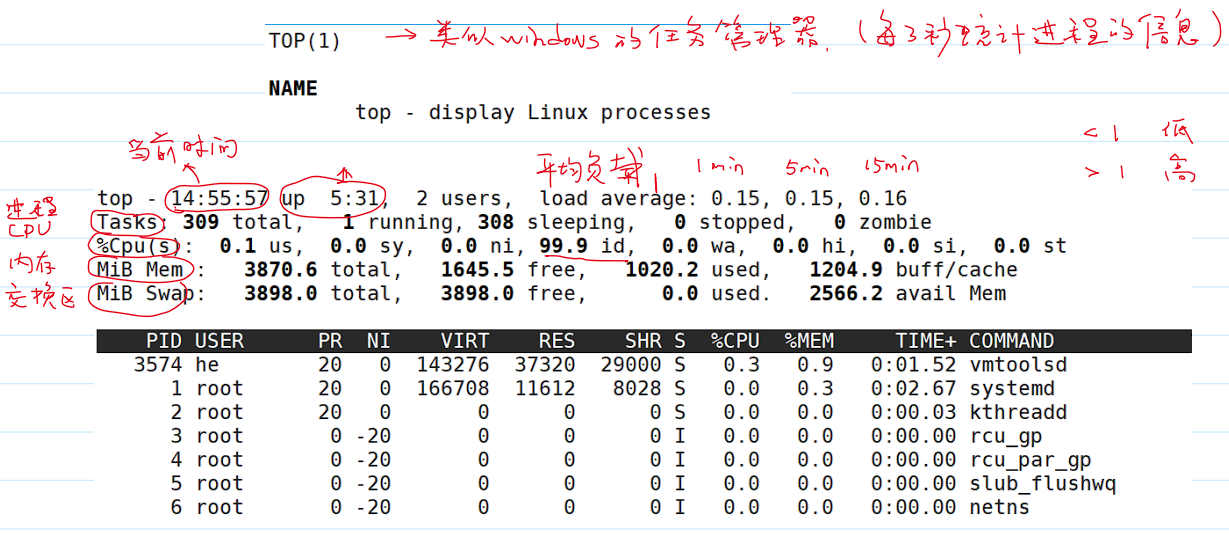
top每 3 秒统计一次进程信息:
pstree打印进程树:

- 前台进程:

- 后台进程:

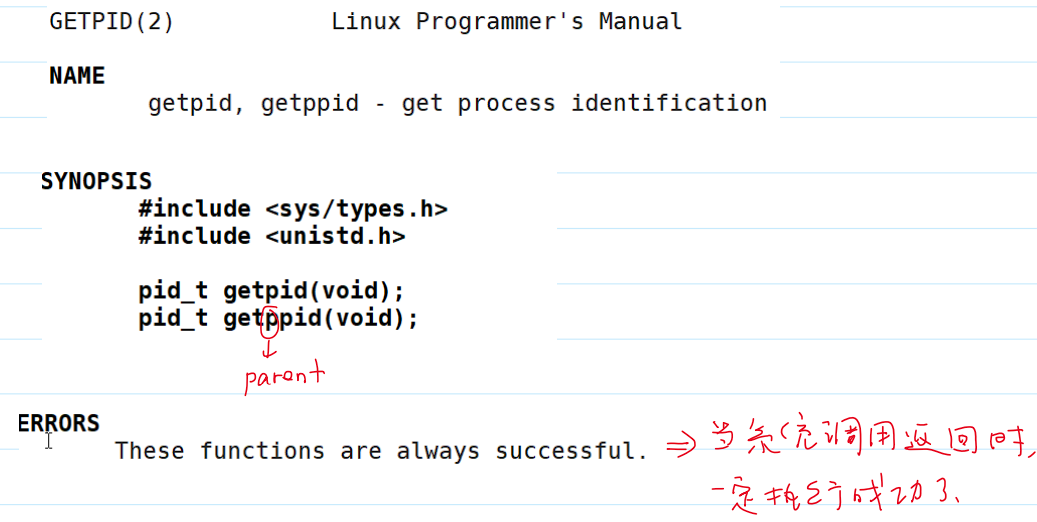
获取进程的标识
- 获取进程的标识的用法:
- 代码示例:
1 | |
- 运行结果:
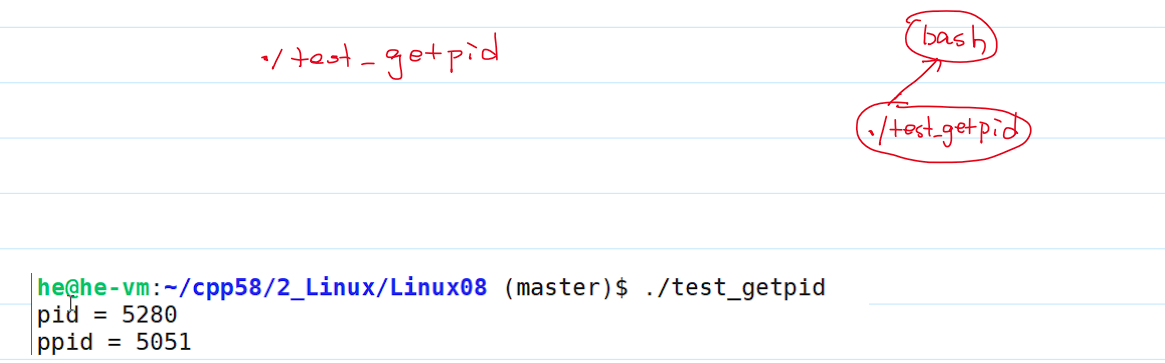
Linux进程id的分配策略:
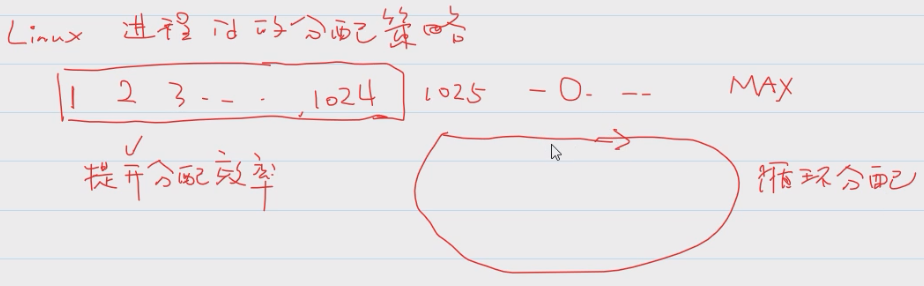
进程的基本操作
- 创建进程:
fork() - 终止进程:
exit()、_exit()、abort()、wait()、waitpid() - 执行程序:
exec函数簇
创建进程:fork()
- 系统调用
fork()的用法:
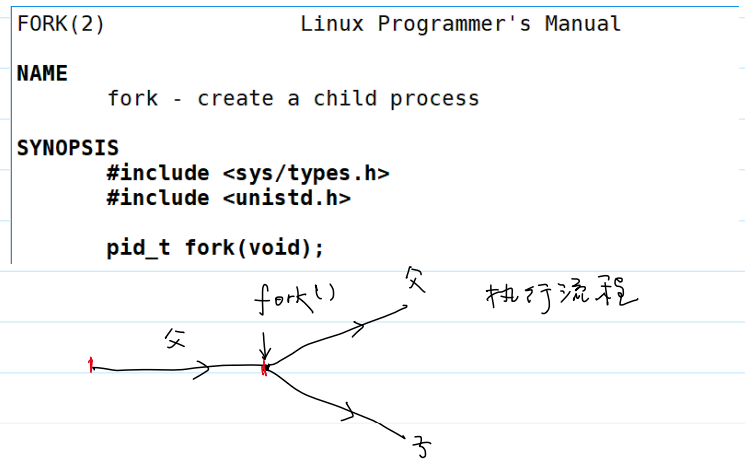
-
系统调用
fork()的返回值:- 成功:
- 父进程:子进程的
pid - 子进程:
0
- 父进程:子进程的
- 失败:
- 父进程:
-1,并且不会创建子进程,设置errno。
- 父进程:
- 成功:
-
惯用法代码:
1 | |
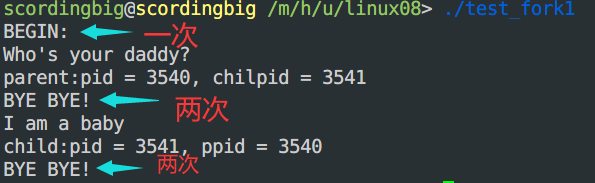
- 测试结果:
- 到底是父进程先执行还是子进程先执行是不确定的(不能假定到底是谁先执行)。
- 系统调用
fork()的原理:
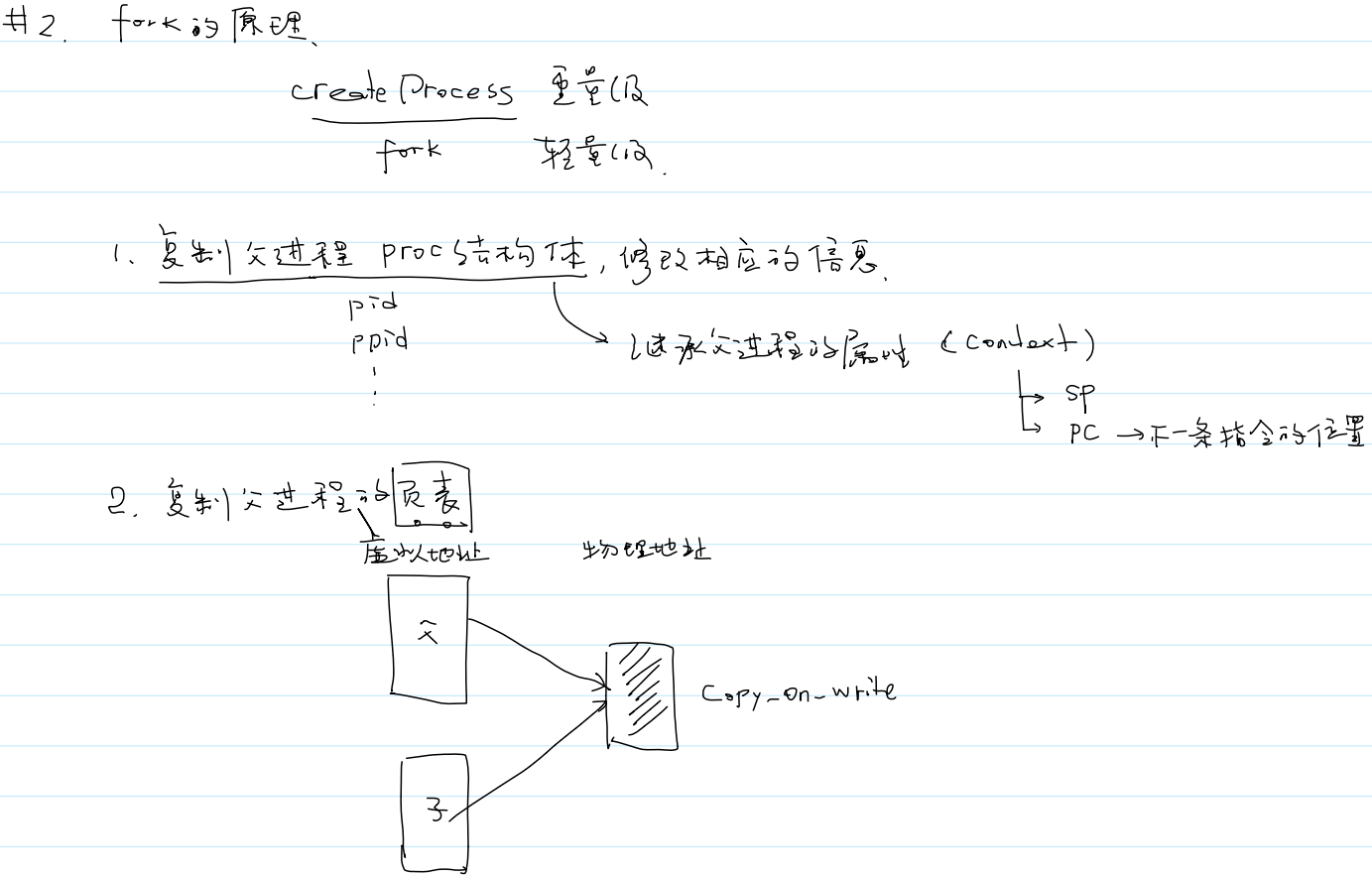
代码段:父子进程共享(不能修改)
- 栈、堆、数据段(父子进程私有)
- 测试代码:
1 | |
- 测试结果:

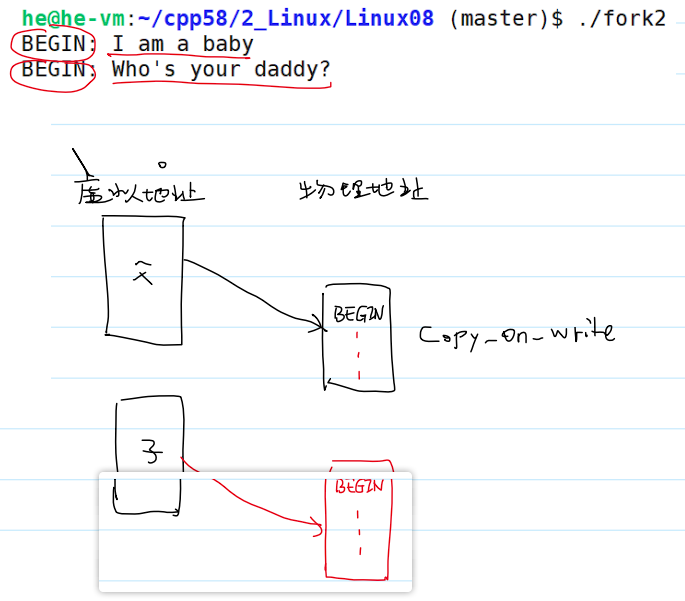
用户态缓冲区(文件流):父子进程是私有的
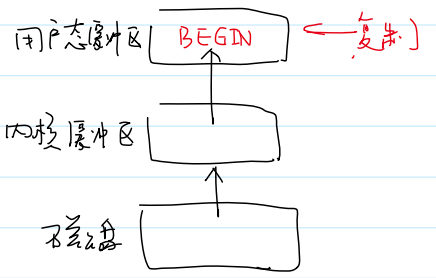
- 测试代码:
1 | |
- 测试结果:
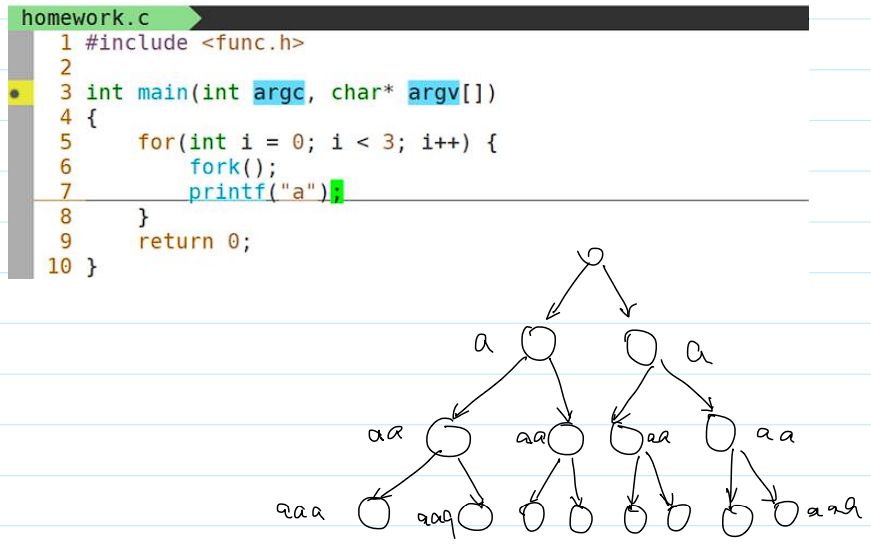
- 用户缓冲区父子进程私有经典题目一:
- 总共输出 24 个
a。
- 总共输出 24 个
- 用户缓冲区父子进程私有经典题目二:
- 总共输出 14 个
a。
- 总共输出 14 个

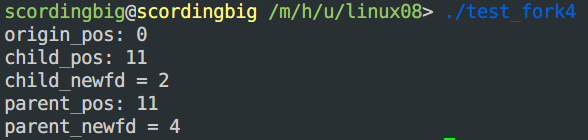
打开文件(共享的)、文件描述符列表(私有的)
- 对于父子进程,打开文件(共享的)、文件描述符列表(私有的)
- 测试代码:
1 | |
- 测试结果:
终止进程
- 基本概念:

正常终止
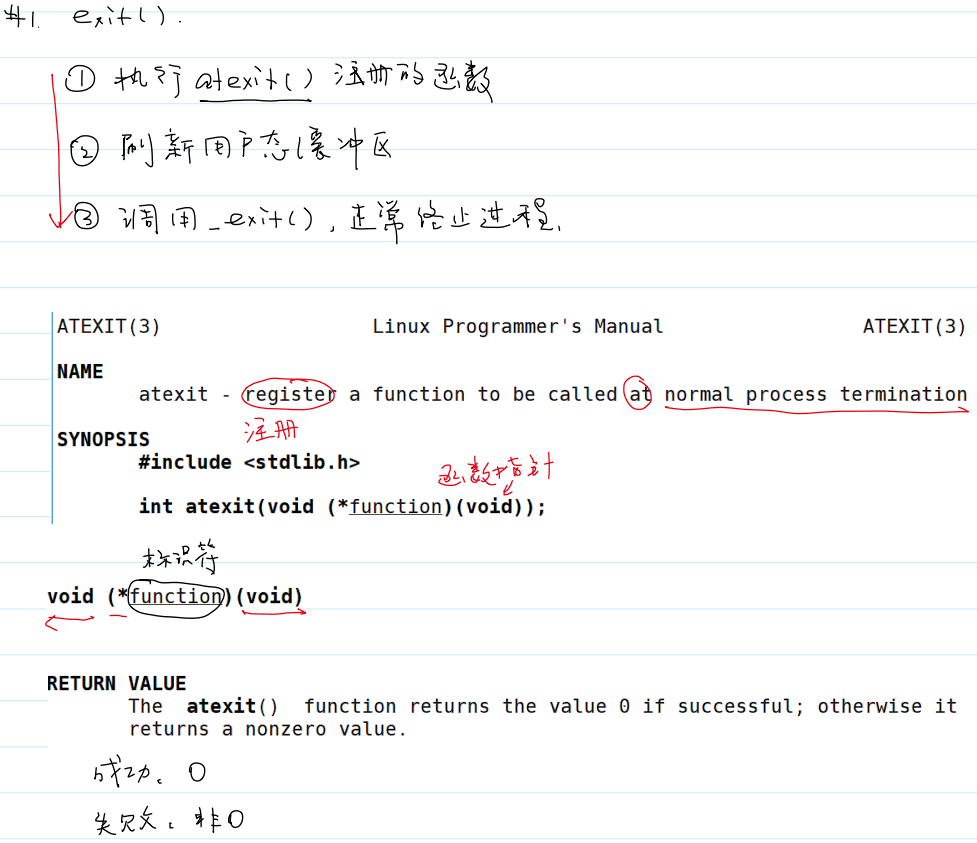
- 库函数
exit()的步骤以及系统调用atexit()的用法和返回值:
- 示例代码:
1 | |
- 测试结果:

- 系统调用
_exit()的用法:- 退出状态码传至操作系统。

- 测试程序:
1 | |
- 测试结果:

异常终止
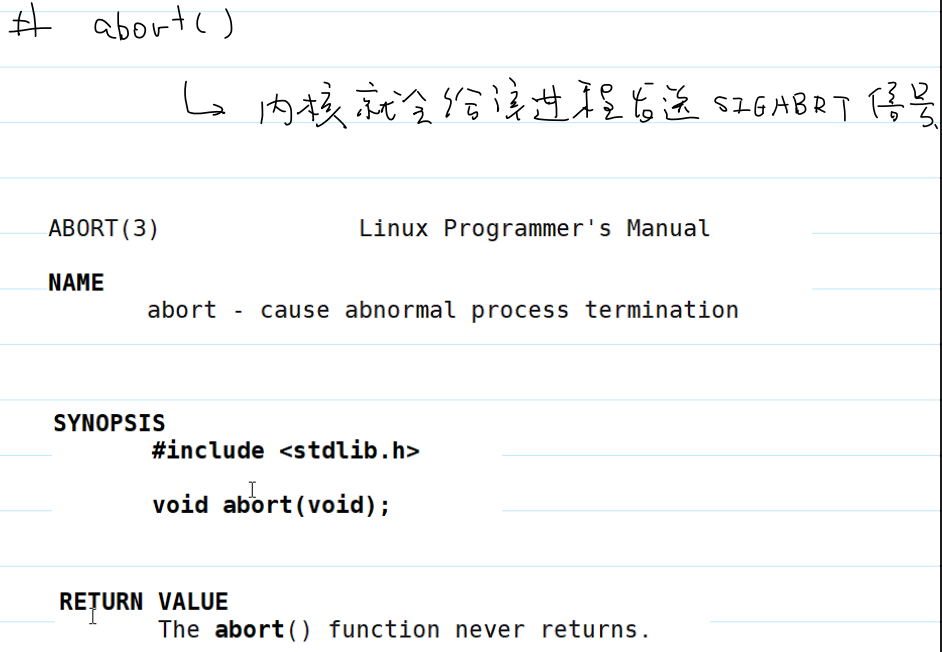
- 系统调用
abort()的用法:
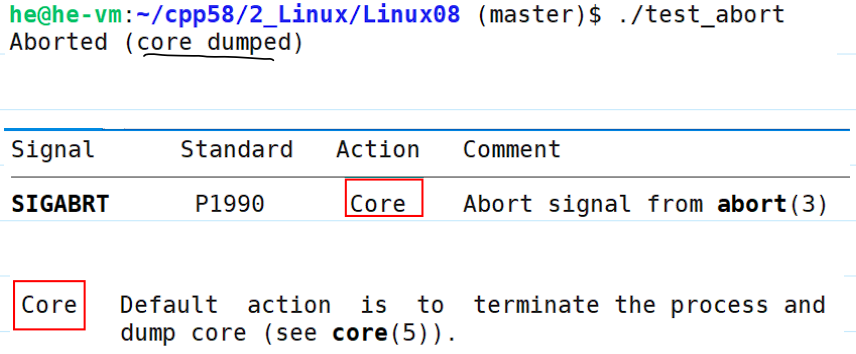
- 测试代码:
1 | |
- 测试结果:

- 内核给该进程发送
SIGABRT信号
孤儿进程和僵尸进程
- 孤儿进程:子进程存活,父进程终止了
- 测试代码:
1 | |
- 测试结果:

- 分析:孤儿进程会被
1号进程(init进程)收养,该进程一直循环执行wait函数。
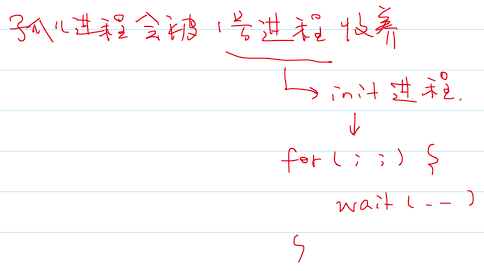
- 僵尸进程:子进程死亡时,有一些信息会保存在内核(
pid、退出状态、CPU 时间…),方便父进程以后查看这个信息,并且给父进程发送SIGCHLD信号,但父进程默认会忽略信号。- 如何给僵尸进程收尸:
wait、waitpid。
- 如何给僵尸进程收尸:
wait()
- 系统调用
wait()的用法和返回值:

- 测试程序:
1 | |
- 测试结果:

waitpid()
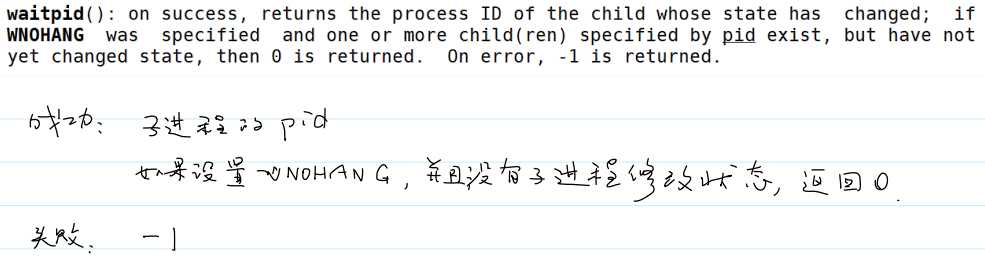
- 系统调用
waitpid()的用法:

- 系统调用
waitpid()的返回值:
- 测试程序:
1 | |
- 测试结果:

exec 函数簇
环境变量 env 的定义:
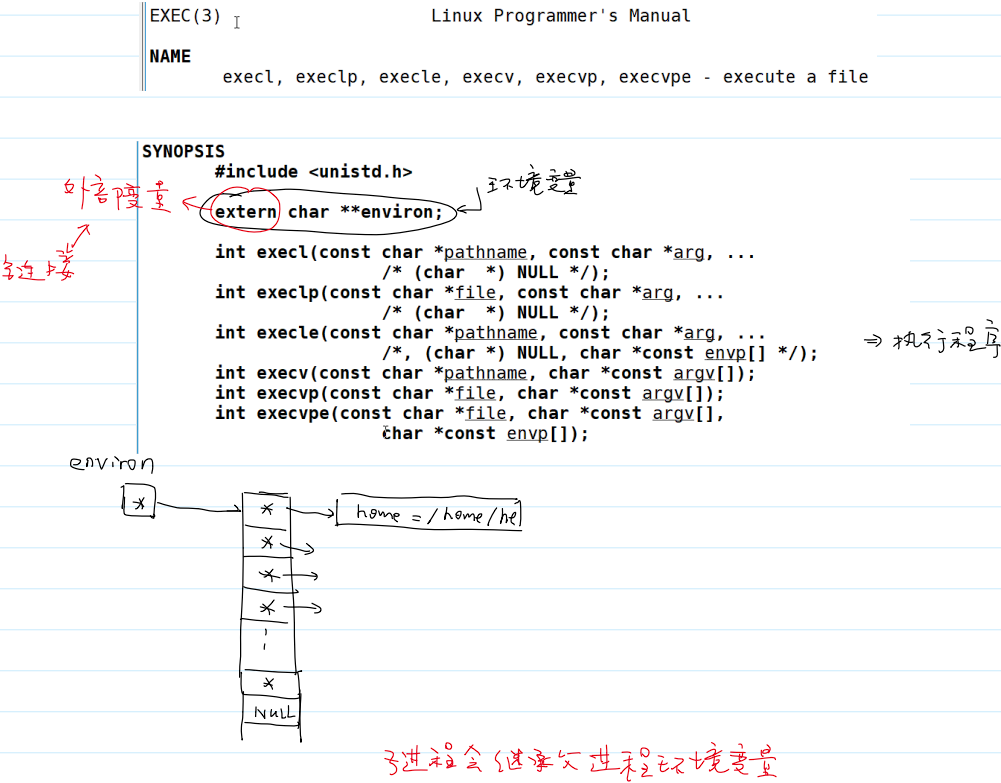
- 打印环境变量
env测试程序:
1 | |
- 测试结果:
exec 函数簇
exec函数簇的用法:
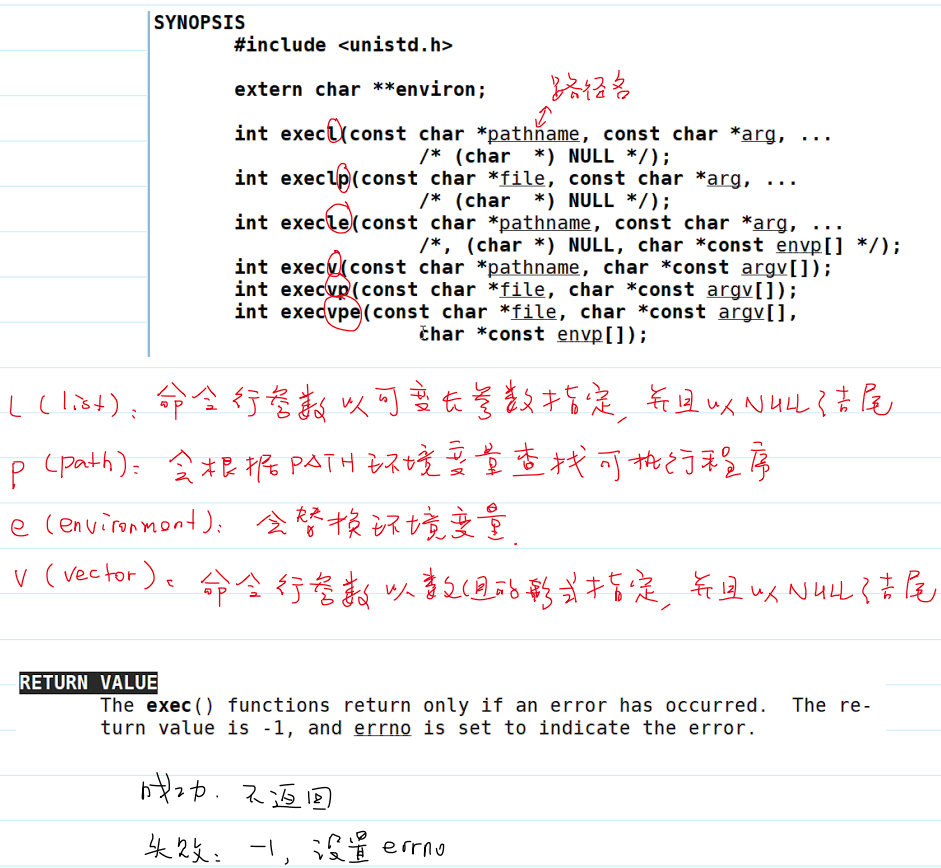
exec函数簇的测试程序:
1 | |
- 测试结果:
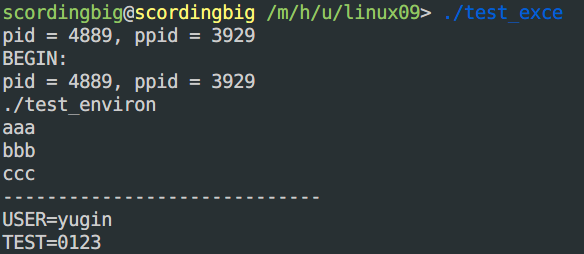
exec现象和原理:- 从上图可以看到,
pid和ppid没有改变,因此没有创建新的进程,并且在新的可执行程序mian函数的第一行开始执行。 - 原理在于:
- 执行
exec函数簇会清除进程的代码段、数据段、堆、栈、上下文; - 加载新的可执行程序(设置代码段、数据段);
- 从新的可执行程序
mian函数的第一行开始执行。
- 执行
- 从上图可以看到,
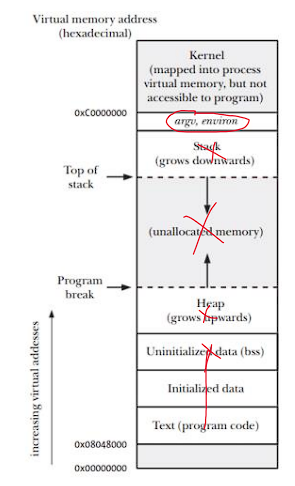
- 清除进程的代码段、数据段、堆、栈、上下文如下图所示:
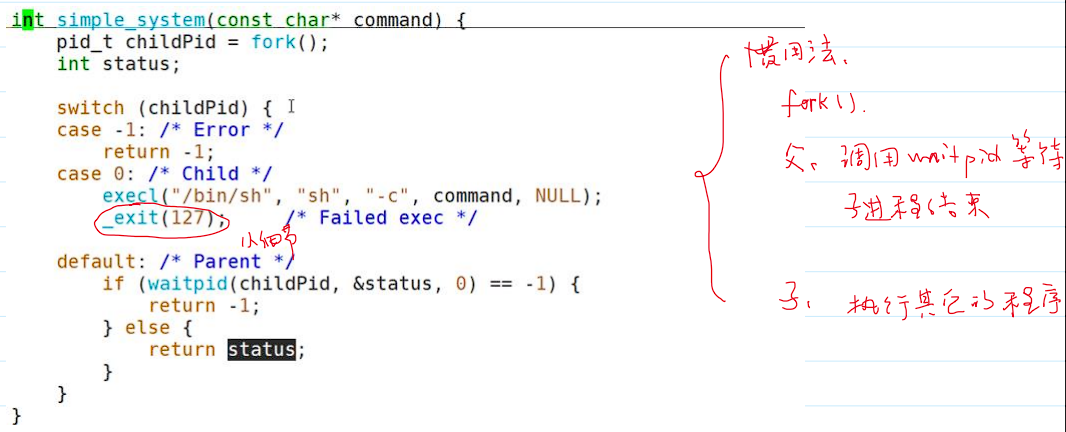
system 的实现和惯用法
system()系统调用的用法:

- 简易
system()的实现代码:
1 | |
- 惯用法说明:
Simple_shell 的实现
- 使用
exec函数簇实现建议shell:
1 | |
进程间通信
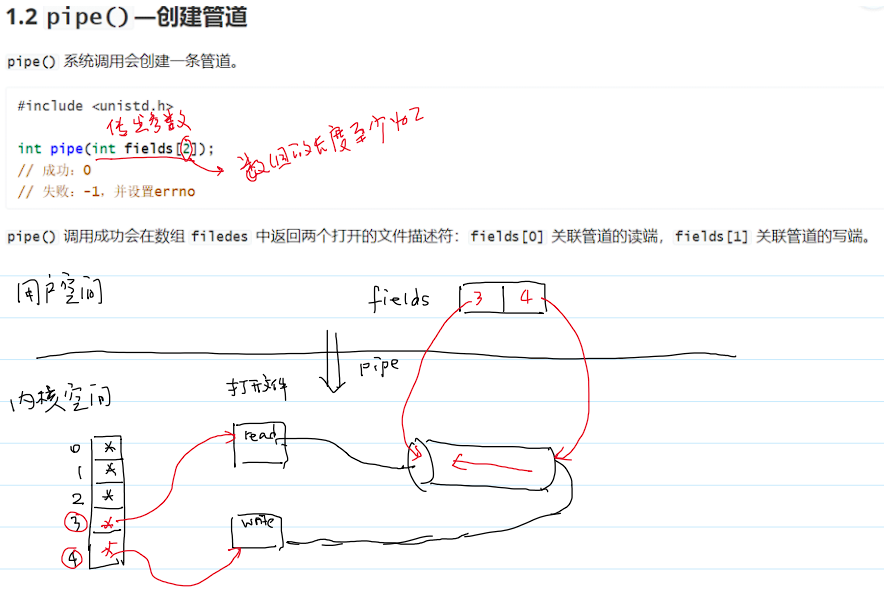
管道 pipe
- 管道:内核管理的一个数据结构
- 管道需要读端和写端都就绪,
open才会返回。 - 当写端写入数据时,
read才会返回,否则是阻塞状态。 - 如果写端关闭,读端是可以读到剩余数据,如果数据读完了,读端会读到
EOF(read会返回0);
- 管道需要读端和写端都就绪,
- 创建管道:
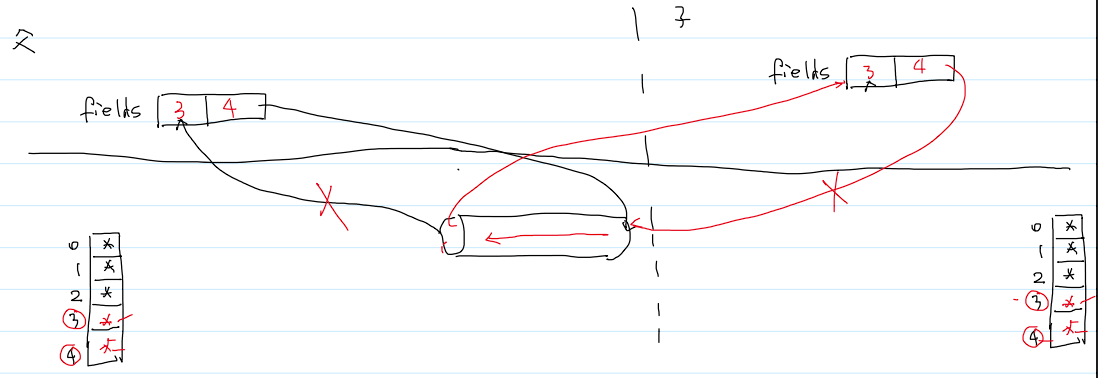
- 进程间管道通信惯用法:
- 先
pipe - 再
fork - 父进程关闭管道一端
- 子进程关闭管道的另一端
- 先
- 代码:
1 | |
有名管道 mkfifo
- 有名管道
mkfifo:- 管道需要读端和写端都就绪,
open才会返回。 - 当写端写入数据时,
read才会返回,否则是阻塞状态。 - 如果写端关闭,读端是可以读到剩余数据,如果数据读完了,读端会读到
EOF(read会返回0); - 如果读端关闭,往管道写数据,内核发送
SIGPIPE信号。
- 管道需要读端和写端都就绪,

五种 I/O 模型
- 五种
I/O模型:

多路 I/O 复用
select 系统调用
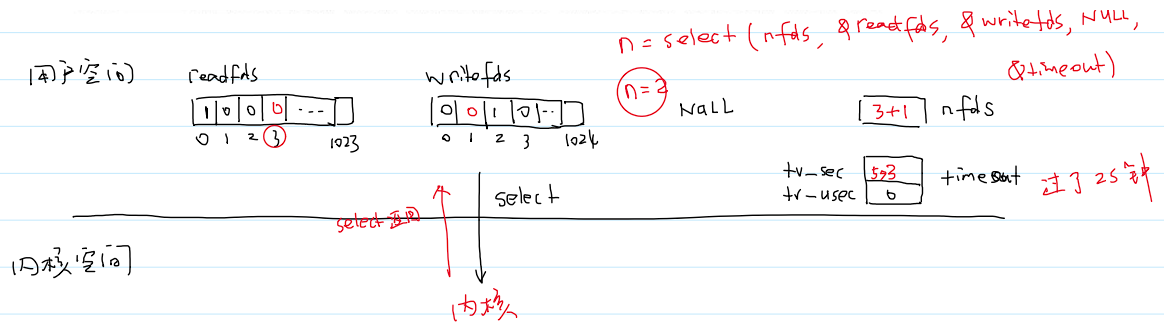
select系统调用用法:- 作用:将多个阻塞点变成一个阻塞点!
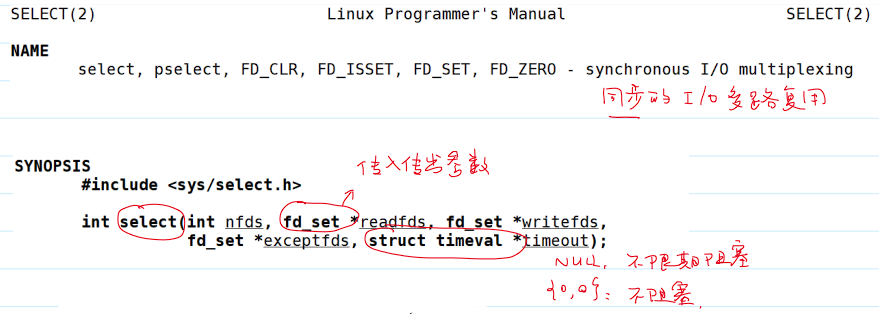
select系统调用参数:

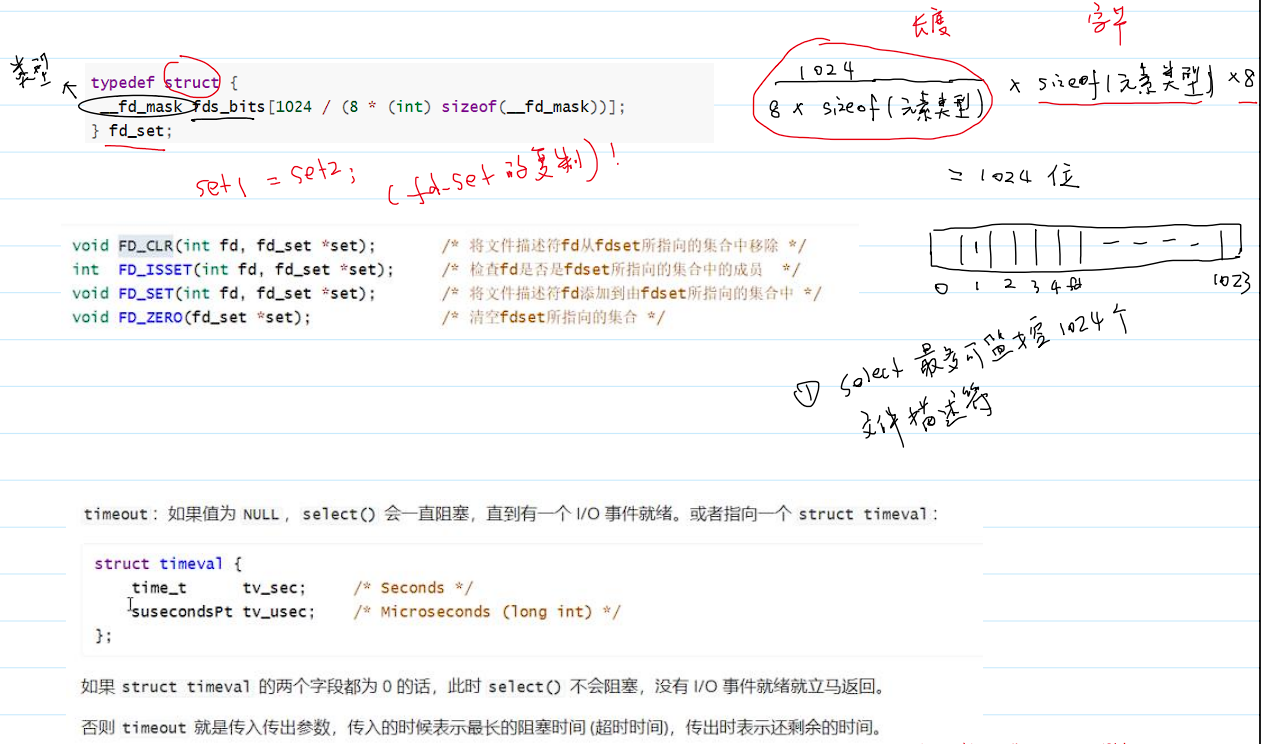
select系统调用详细参数和使用方法:
select系统调用工作原理:
- 使用
select系统调用实现点对点聊天系统:- 需要注意的点:如果一方将管道写端关闭了,
read系统调用会一直读,但返回值是 0,即读到 0 个 Bytes。
- 需要注意的点:如果一方将管道写端关闭了,
- 用户 1 代码:
1 | |
- 用户 2 代码:
1 | |
select系统调用的缺陷:- 监听的文件描述符的个数是有限的;
- 当
select系统调用返回时,还需要遍历fd_set,找到就绪的文件描述符。
信号
基本概念
- 信号是内核通知应用程序外部事件的一种机制。
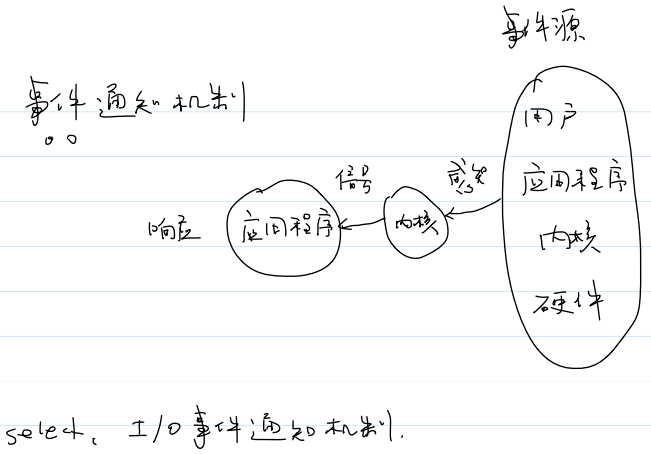
- 事件源:

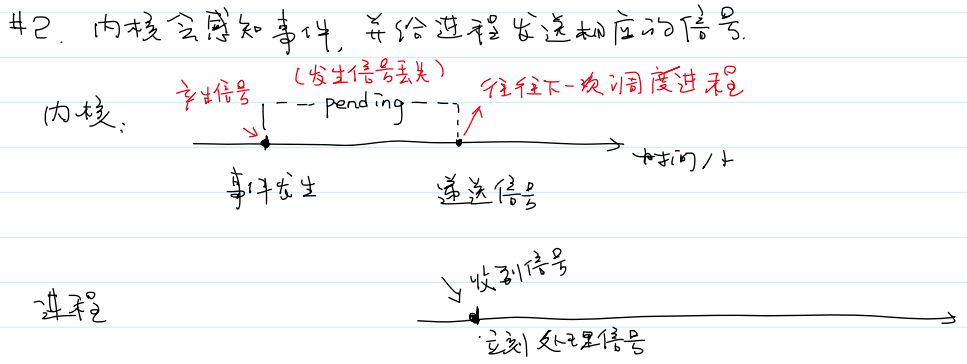
- 内核会感知事件,并给进程发送相应的信号。
- 信号的处理方式:

- 标准信号 1:
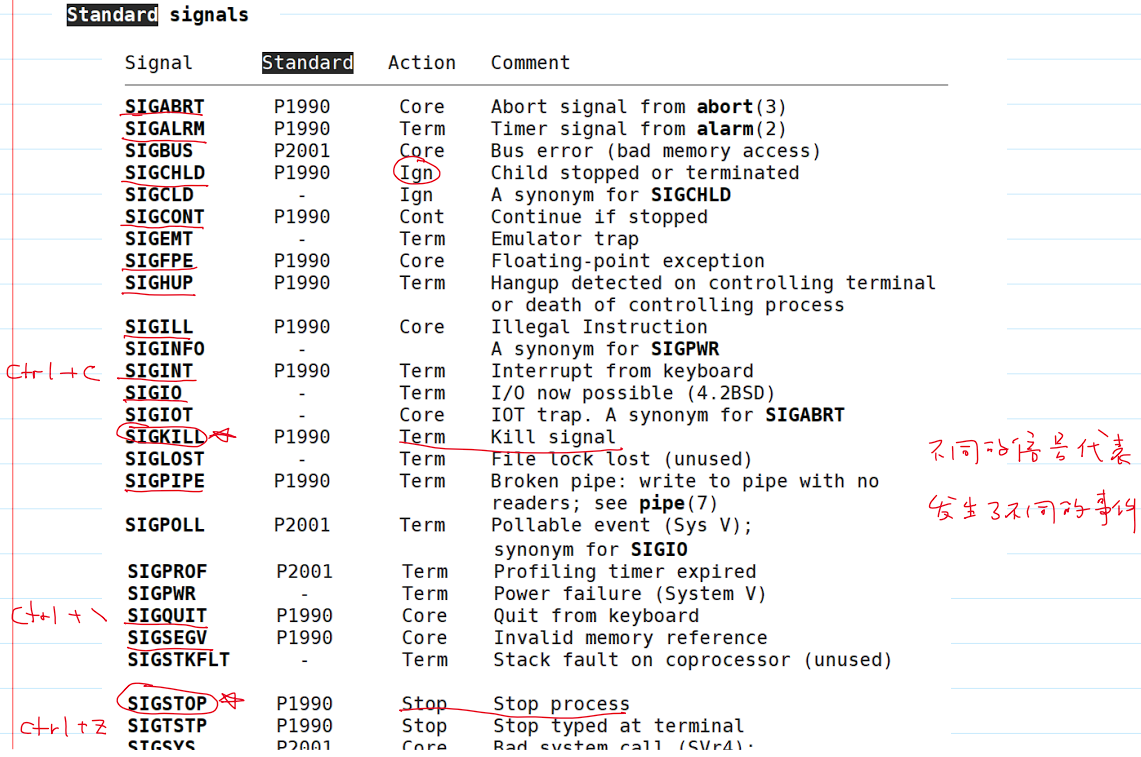
- 标准信号 2:

信号的执行流程
- 注册信号处理函数:
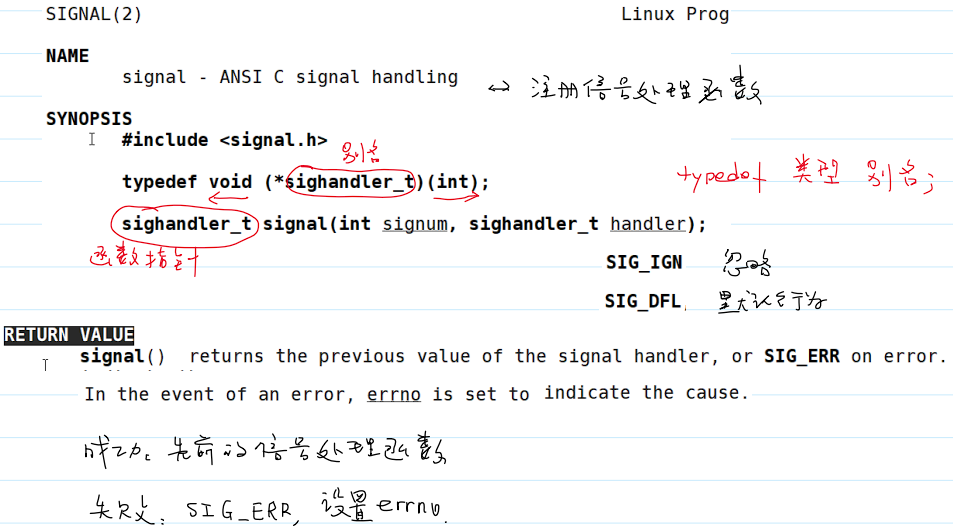
- 示例代码:
1 | |
- 信号的处理流程:
- 注册函数是跑在用户态的。
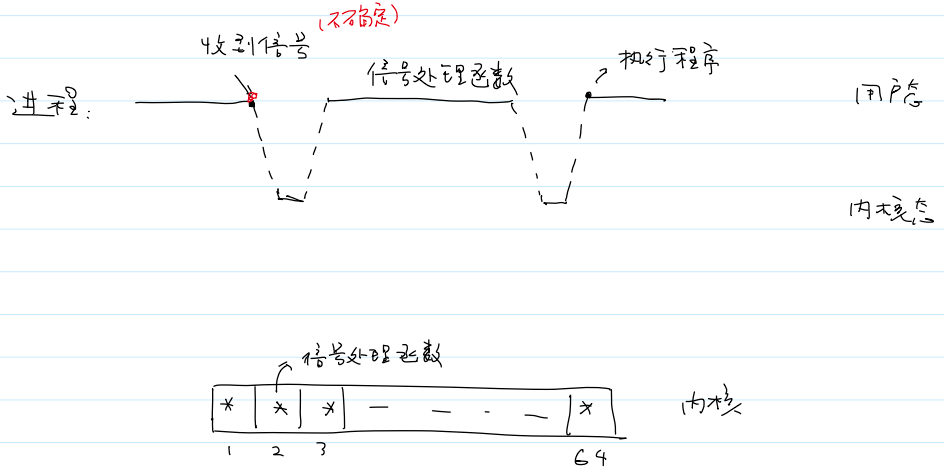
- 信号的特点:
- 不稳定;
- 异步的(什么时候收到信号是不确定的,收到信号后,会立刻马上执行信号处理函数);
- 不同心态关于信号的语义也不一样。
注册信号处理函数
- 注册信号处理函数:
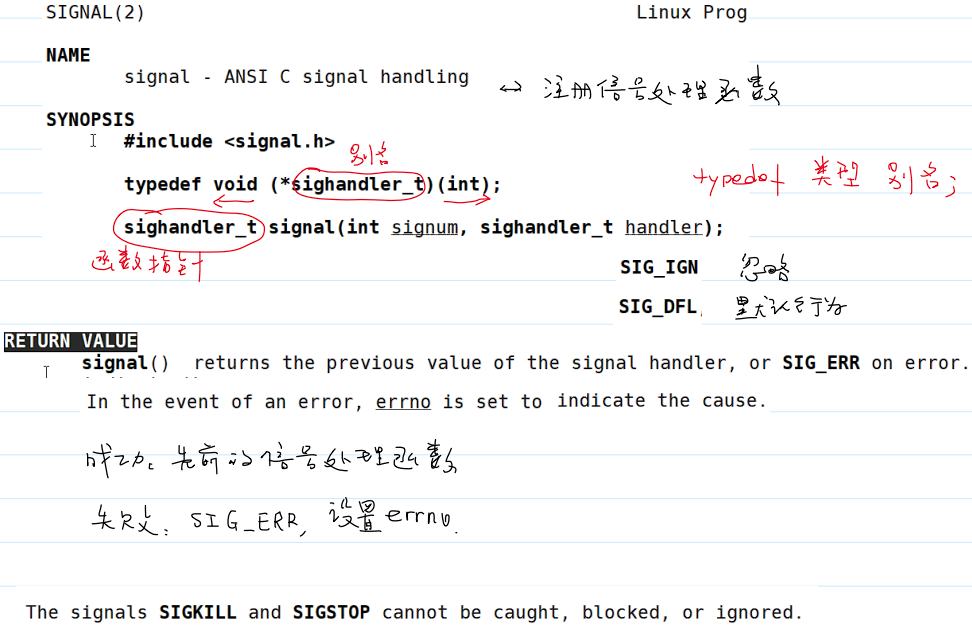
- 示例代码 1:
1 | |
- 示例代码 2:
1 | |
发送信号
kill命令:
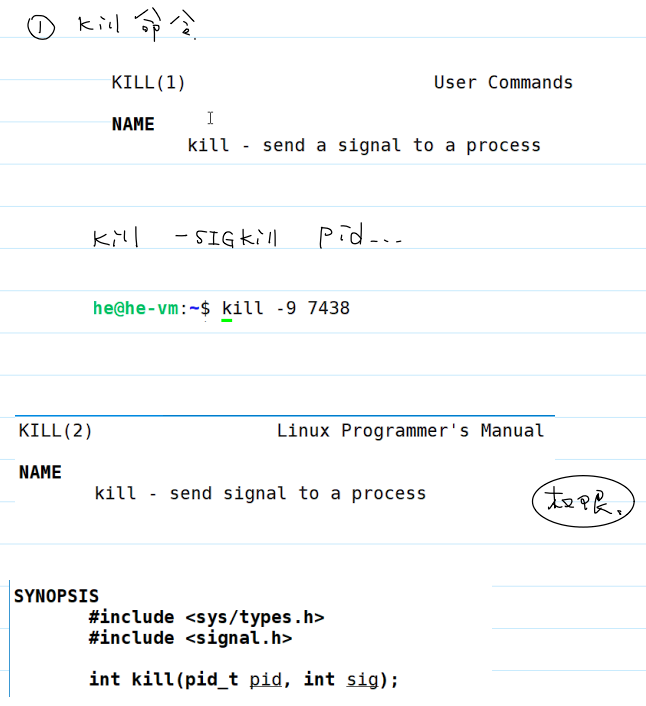
pid相关权限和返回值:

- 示例代码:
1 | |
线程
- 线程:一条执行的流程。
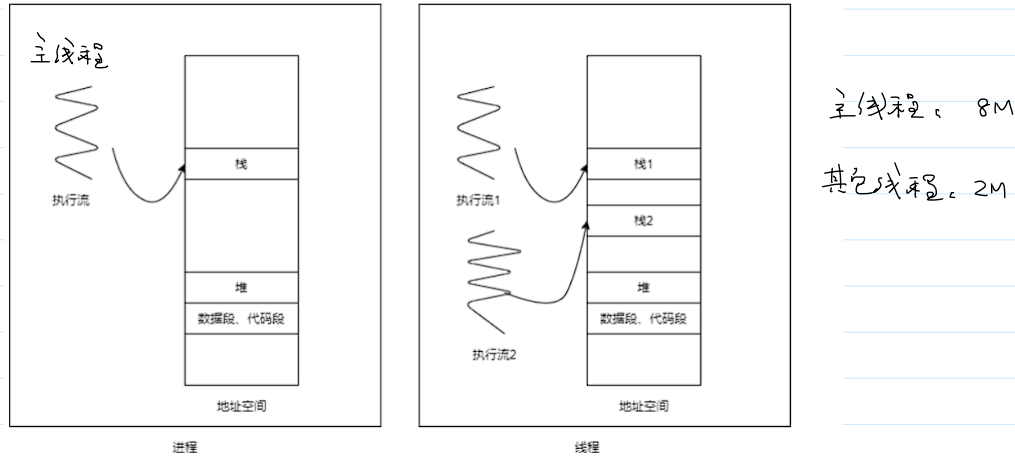
- 引入线程:
- 进程是资源分配的最小单位;
- 线程是调度的最小单位;
- 线程共享进程的所有资源。
- 为什么要引入线程?
- 进程之间的切换(
CPU的高速缓存,TLB失效),开销大。用进程中的线程之间切换,开销较小。 - 进程之间通信,需要打破隔离避障,线程之间的通信,开销较小。
- 进程的创建和销毁比较耗时,而线程的创建和销毁要轻量很多。
- 进程之间的切换(
线程的基本操作和创建线程
- 获取线程的标识:
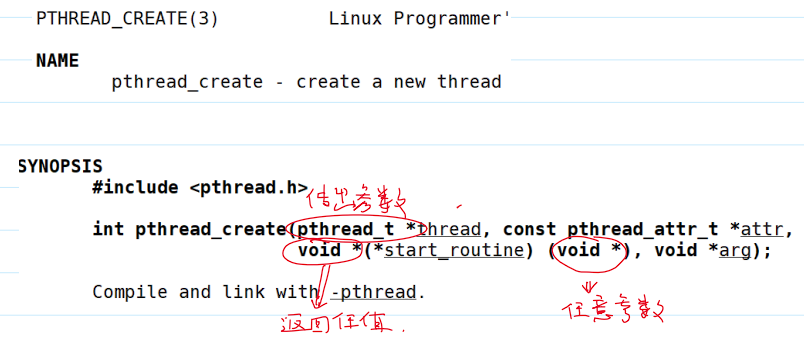
- 创建线程:
pthread库设计原则:- 返回值是
int类型,表示调用成功或失败。- 成功:
0; - 失败:错误码,不会设置
errno。
- 成功:
thread_t:返回时,存放创建线程ID。attr_t:线程属性,一般填NULL,表示用默认属性。start_routine:线程的入口函数。arg:线程的入口函数的参数。
- 返回值是
- 示例代码:
1 | |
- 运行结果:

- 向线程的入口函数传递参数(
void*)代码:
1 | |
- 运行结果:

终止线程
- 进程的终止:
- 从
main返回 exit()- 收到信号
- 从
- 线程的终止:
- 从
start_routine返回 pthread_exit()pthread_cancel()
- 从
线程显式终止函数
pthread_exit()线程显式终止函数:
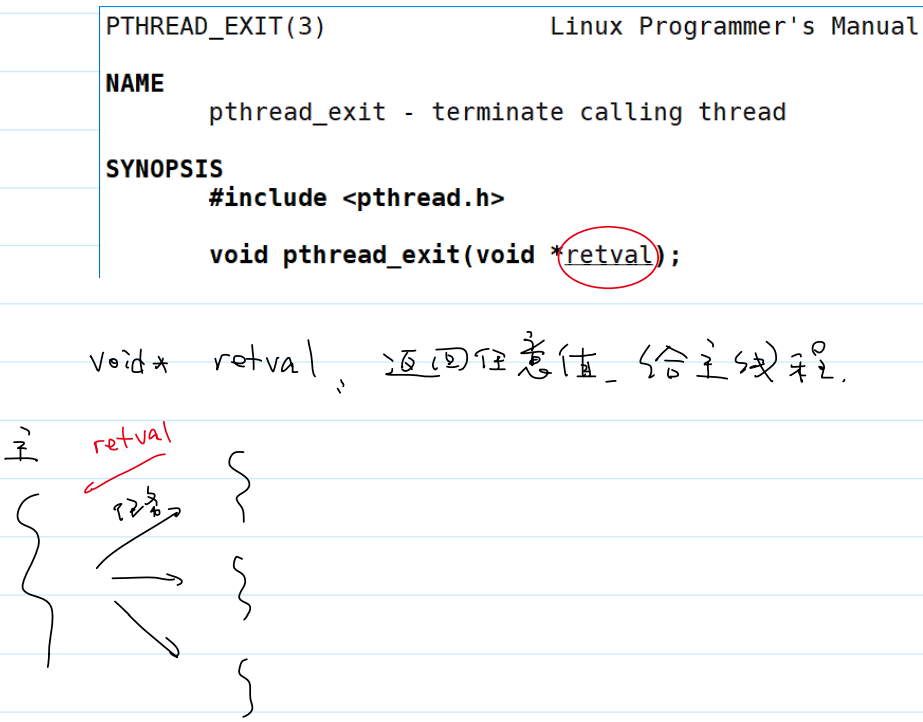
pthread_join()等待一个线程的结束:

- 示例代码(
1到100求和,分两个线程执行):
1 | |
- 运行结果:

- 注意:不能返回指向该线程栈上数据的指针,因为当线程退出时,该线程的栈会销毁。
1 | |
游离线程
pthread_detach()用于将线程设置为游离状态的函数,使线程在终止时自动释放资源:

- 示例代码:
1 | |
- 主线程无法再获取游离线程的返回结果:

线程清理函数
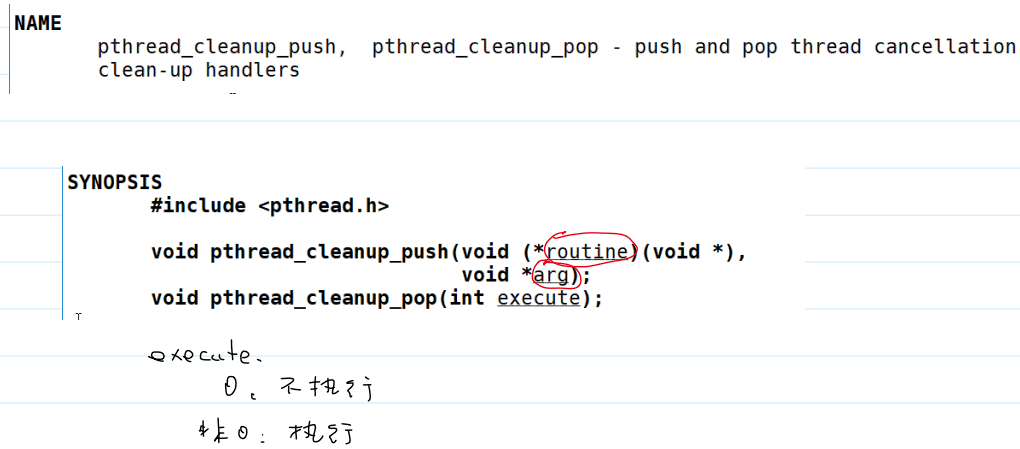
- 线程清理函数:用于在线程退出时执行预定义的清理操作。
execute参数:0:栈中的args参数出栈但不执行cleanup线程清理函数。- 非
0:栈中的args参数出栈并执行cleanup线程清理函数。
- 与进程之间的对比:

- 示例代码:
1 | |
- 运行结果:

- 注意事项:
- 从
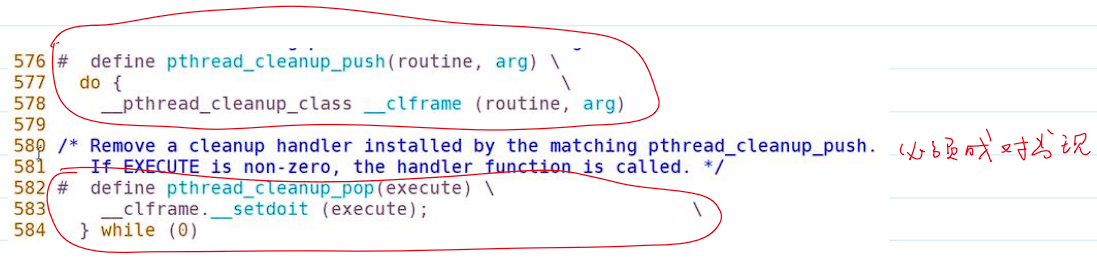
start_routine返回,不会执行线程清理函数。 pthread_cleanup_push和pthread_cleanup_pop必须成对出现。- 必须成对出现的原因在于源码中采用了宏函数的特性。
- 从
线程的同步
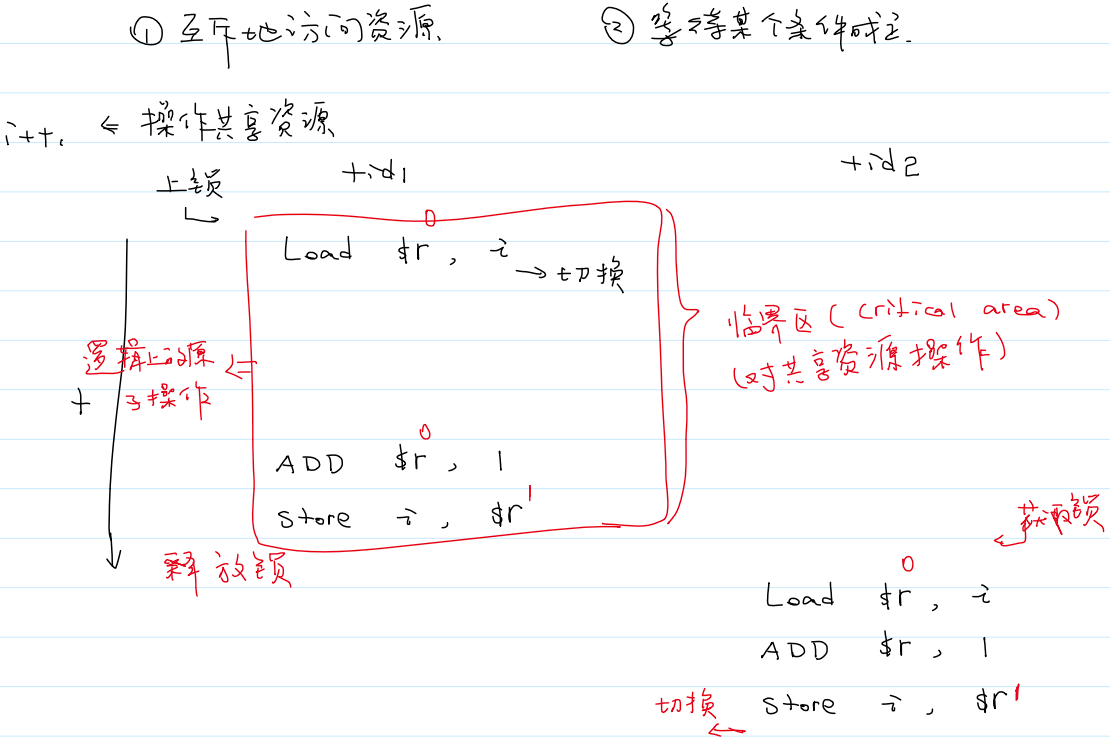
- 原子性:CPU 指令是原子性的。
- 相关术语:
- 竞态条件(
race condition):- 多个执行流程
- 共享资源
- 程序的结果(状态取决于执行流程调度的情况)
- 异步和同步:
- 异步:任何调度情况都可以出现、两个执行流程不做任何交流。
- 同步:让一些调度不可能出现(同步会有一些开销)。
- 互斥锁、条件变量。
- 并发和并行:
- 并发:一种现象,在一个时间段中,执行流程可以交替执行。
- 并行:一种技术,同一时刻,可以执行多个执行流程(并行是并发的一种)。
- 竞态条件(
- 线程的同步:
- 互斥地访问资源
- 等待某个条件成立
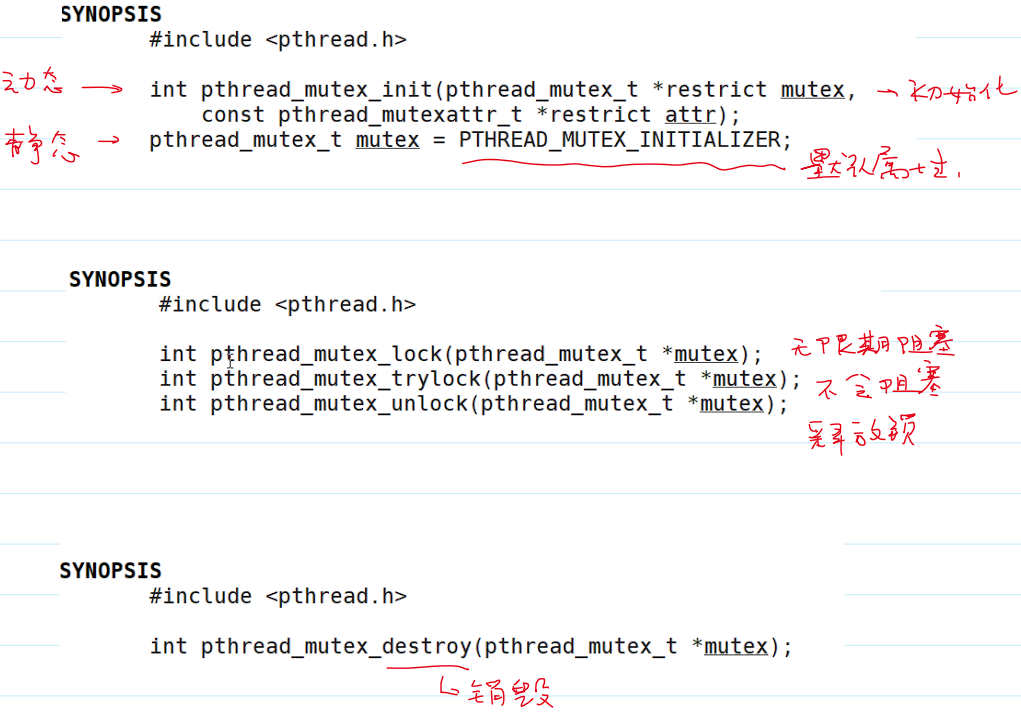
- 互斥锁函数:
- 互斥锁的使用代码:
1 | |
- 运行结果:

- 银行例子(细粒度锁):
1 | |
- 运行结果:

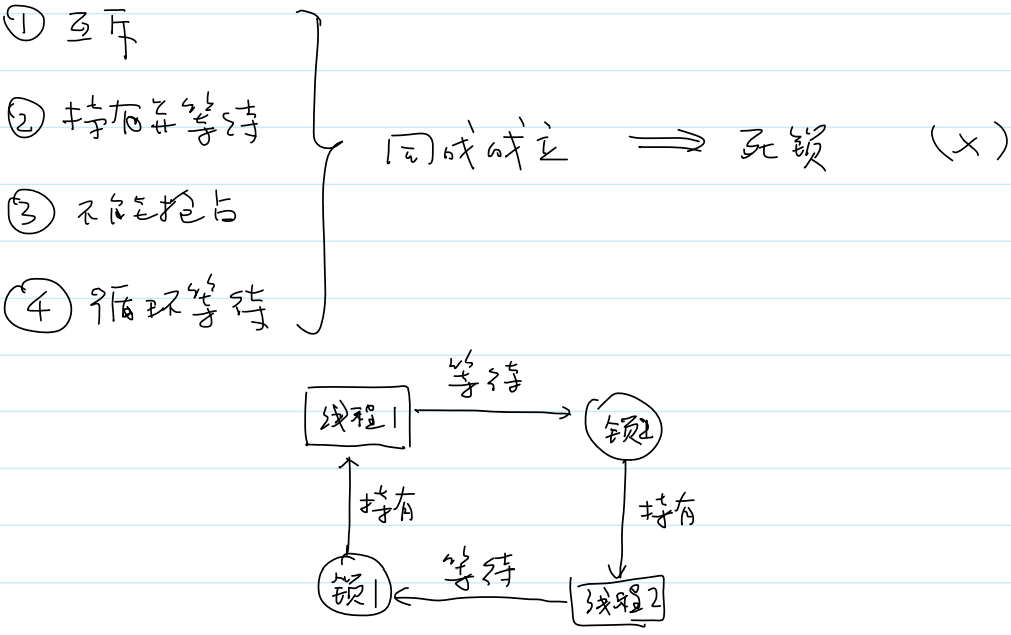
死锁
- 以下四个条件同时成立会造成死锁:
- 互斥
- 持有并等待
- 不能抢占
- 循环等待
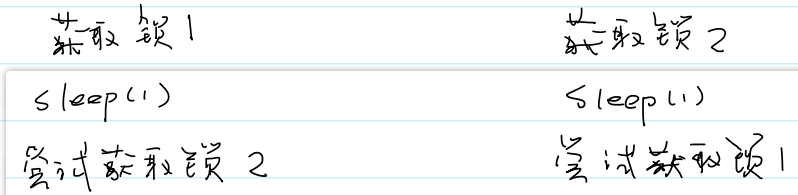
- 死锁代码例子:
1 | |
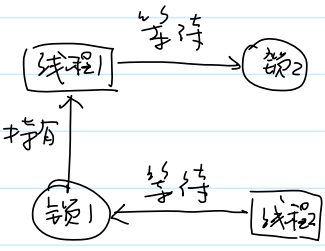
- 三个线程都处于阻塞状态:

- 解决方案 1:破坏循环等待
- 必须按照固定的顺序,依次获取锁:
1 | |
- 运行结果:

- 解决方案 2:不能抢占
1 | |
- 解决方案 3:持有并等待
1 | |
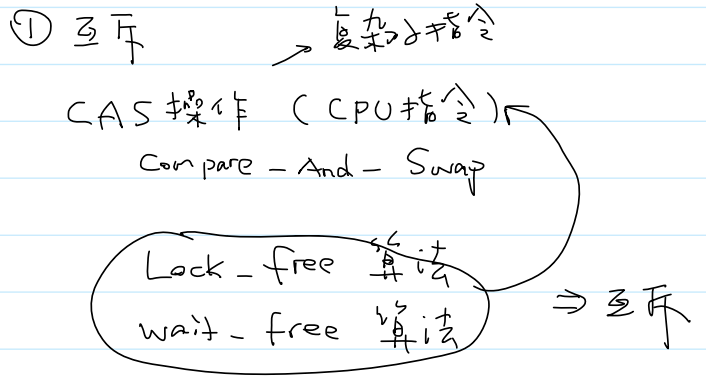
- 解决方案 4:解决互斥,实现原子性
等待条件成立
- 条件变量(
pthread_cond_t):- 条件变量只是提供了一个等待、唤醒机制;
- 至于条件何时成立,何时不成立,取决于业务。
- 1、初始化:

- 2、当条件不成立,等待:

pthread_cond_wait()返回时,条件一定成立吗?- 不一定!
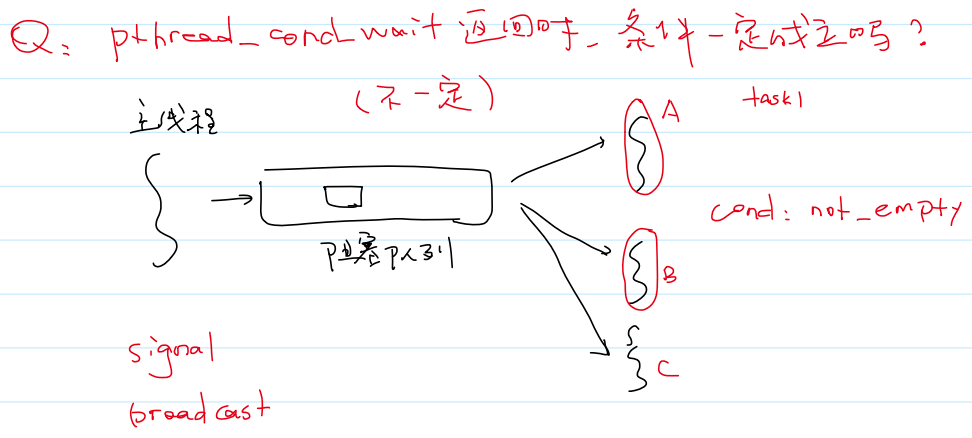
- 3、当条件成立时,唤醒等待的线程:

- 4、销毁
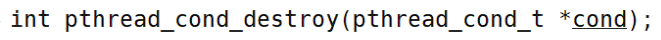
生产者消费者模型
- 生产者消费者模型:
- 阻塞队列:
- 当队列满时,如果线程往阻塞队列中添加东西,线程会陷入阻塞;
- 当队列空时,如果线程往阻塞队列中取出东西,线程会陷入阻塞;
- 生产者,产生任务:
- 如果队列满了,生产者陷入阻塞,等待队列不满(
not_full); - 如果队列不满,将任务添加到阻塞队列,队列非空,唤醒消费者(
not_empty);
- 如果队列满了,生产者陷入阻塞,等待队列不满(
- 消费者,完成任务:
- 如果队列空了,消费者陷入阻塞,等待队列非空(
not_empty); - 如果队列非空,从阻塞队列中获取任务,队列不满,唤醒生产者(
not_full);
- 如果队列空了,消费者陷入阻塞,等待队列非空(
- 阻塞队列:

阻塞队列
- 阻塞队列(有界队列):
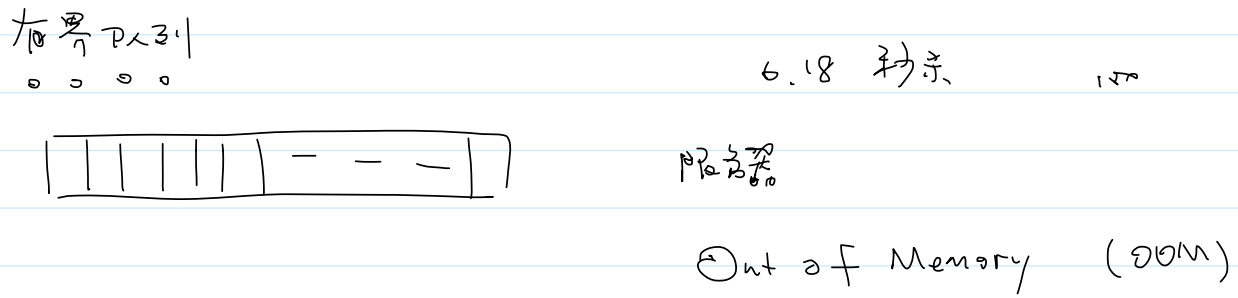
blockQ.h文件:
1 | |
blockQ.c文件:
1 | |
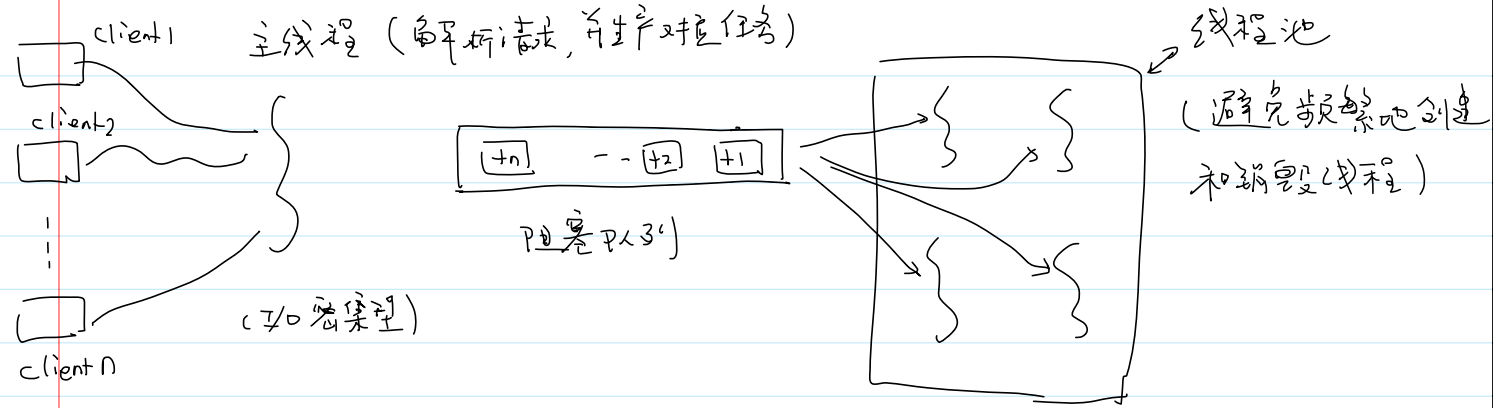
实现生产者消费者模型
- 通过线程池(能够避免频繁地创建和销毁线程)实现生产者消费者模型:
- 应用程序应该包含多少个线程要通过两个方面考虑:
- CPU 的核数
- 任务的负载
I/O密集型任务- 计算密集型任务

- 代码示例:
1 | |
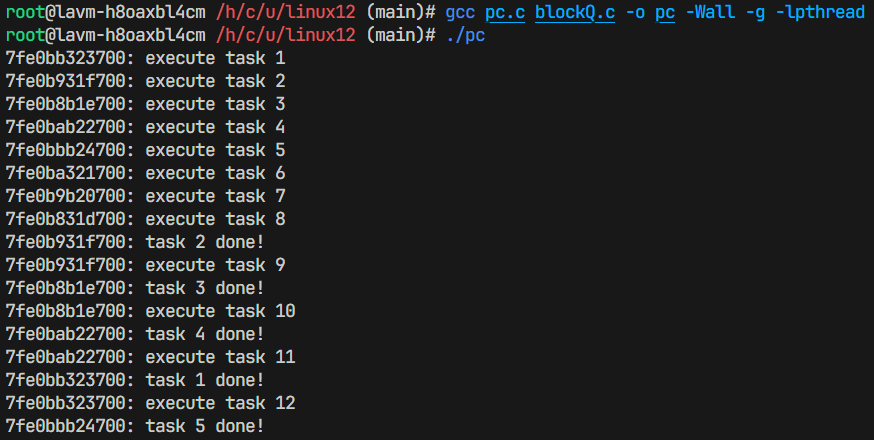
- 生产者消费者模型运行结果:
Linux 系统编程
http://example.com/2025/05/18/linux_program/